毕设参考文献调研
学士论文推荐参考文献数量是30篇
目前打算找30篇论文进行阅读学习,筛选能用的,然后注意参考文献的参考文献可以补充上去
国内10篇 国外20篇 暂定基于大语言模型的社交媒体模拟与信息传播机制的分析与研究
Analysis and research of social media simulation and information dissemination mechanism based on large language model
权威期刊
| 类型/领域方向 | 期刊/会议名称 | 主办单位/出版社 | 领域方向 |
|---|---|---|---|
| 国内期刊 | 计算机学报 | 中国计算机学会 | 计算机科学,包括消息传递机制;人工智能、自然语言处理及大语言模型 |
| 软件学报 | 中国科学院软件研究所 | 软件工程、分布式系统,涉及消息传递机制;人工智能、机器学习及大语言模型 | |
| 自动化学报 | 中国自动化学会 | 自然语言处理、深度学习及大语言模型 | |
| 中文信息学报 | 中国中文信息学会 | 中文自然语言处理,包括大语言模型 | |
| 电子学报 | 中国电子学会 | 电子与信息科学,包括通信协议和消息传递机制;人工智能、自然语言处理及大语言模型 | |
| 通信学报 | 中国通信学会 | 通信技术,涉及消息传递机制 | |
| 国际期刊 | IEEE Transactions on Parallel and Distributed Systems (TPDS) | IEEE | 并行与分布式系统,涵盖消息传递机制 |
| IEEE Transactions on Computers | IEEE | 计算机系统与架构,包括消息传递机制 | |
| Journal of Parallel and Distributed Computing (JPDC) | Elsevier | 并行与分布式计算,涉及消息传递机制 | |
| ACM Transactions on Computer Systems (TOCS) | ACM | 计算机系统,包括消息传递机制 | |
| Distributed Computing | Springer | 分布式计算,涉及消息传递机制 | |
| Computer Networks | Elsevier | 计算机网络,包括消息传递机制 | |
| IEEE/ACM Transactions on Networking | IEEE/ACM | 网络技术与协议,包括消息传递机制 | |
| IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) | IEEE | 模式识别与机器学习,涵盖大语言模型 | |
| Journal of Machine Learning Research (JMLR) | JMLR | 机器学习,发表大语言模型的理论与算法 | |
| Artificial Intelligence (AI Journal) | Elsevier | 人工智能,涵盖大语言模型的研究与应用 | |
| Computational Linguistics | MIT Press | 自然语言处理,包括大语言模型 | |
| IEEE Transactions on Neural Networks and Learning Systems (TNNLS) | IEEE | 深度学习与神经网络,包括大语言模型 | |
| Nature Machine Intelligence | Nature | 人工智能,发表大语言模型的前沿研究 | |
| Transactions of the Association for Computational Linguistics (TACL) | ACL | 计算语言学,发表大语言模型的研究 | |
| 顶级会议 | ACM Symposium on Principles of Distributed Computing (PODC) | ACM | 分布式计算原理 |
| IEEE International Conference on Distributed Computing Systems (ICDCS) | IEEE | 分布式计算系统 | |
| ACM SIGCOMM Conference on Data Communication | ACM | 数据通信与网络 | |
| IEEE International Parallel & Distributed Processing Symposium (IPDPS) | IEEE | 并行与分布式处理 | |
| NeurIPS (Conference on Neural Information Processing Systems) | NeurIPS | 机器学习与人工智能,涵盖大语言模型 | |
| ICML (International Conference on Machine Learning) | ICML | 机器学习,发表大语言模型的算法与理论 | |
| ACL (Annual Meeting of the Association for Computational Linguistics) | ACL | 自然语言处理,专注于大语言模型 | |
| EMNLP (Conference on Empirical Methods in Natural Language Processing) | ACL | 自然语言处理,涵盖大语言模型 | |
| AAAI (Association for the Advancement of Artificial Intelligence) | AAAI | 人工智能,发表大语言模型的研究 | |
| ICLR (International Conference on Learning Representations) | ICLR | 深度学习,涵盖大语言模型的训练与优化 | |
| CVPR (Conference on Computer Vision and Pattern Recognition) | IEEE | 计算机视觉,涉及多模态大语言模型 |
查找论文网站
国内 :
- 中国知网(CNKI) 网址: https://www.cnki.net/
- 万方数据 网址: https://www.wanfangdata.com.cn/
国外 :
- Google Scholar 网址: https://scholar.google.com/
- IEEE Xplore 网址: https://ieeexplore.ieee.org/
找到的论文
国外
- S3: Social-network Simulation System with Large Language Model-Empowered Agents
- S3: 社交网络模拟系统 大型语言模型赋能的代理
- https://ar5iv.labs.arxiv.org/html/2307.14984?_immersive_translate_auto_translate=1
- 在这项工作中,我们利用大型语言模型 ()LLMs 在感知、推理和行为方面的类似人类的能力,并利用这些品质来构建 S3 系统(Social network Simulation System 的缩写)。遵循广泛采用的基于智能体的模拟范式,我们采用微调和提示工程技术,以确保智能体的行为与社交网络中真实人类的行为密切相关。具体来说,我们模拟了三个关键方面:情绪、态度和交互行为。通过赋予系统中的代理感知信息环境和模拟人类行为的能力,我们观察到群体层面现象的出现,包括信息、态度和情感的传播。我们采用真实的社交网络数据,进行包括两个级别的模拟的评估。令人鼓舞的是,结果显示出有希望的准确性。这项工作代表了由LLM基于代理的社交网络模拟领域的第一步。我们预计我们的努力将成为开发模拟系统的灵感源泉,但不限于社会科学。
- A Survey of Information Dissemination Model, Datasets, and Insight
- 信息传播模型、数据集和洞察调查
- From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents
- 从个人到社会:基于大型语言模型的代理驱动的社会模拟调查
- Unveiling the truth and facilitating change: Towards agent-based large-scale social movement simulation
- 揭开真相并促进变革:迈向基于智能体的大规模社会运动模拟
S3: Social-network Simulation System with Large Language Model-Empowered Agents S3: 社交网络模拟系统 大型语言模型赋能的代理
- 无源码
AI4SS | Unveiling the Truth and Facilitating Change: Towards Agent-based Large-scale Social Movement Simulation | 揭示真相与促进变革:迈向基于代理的大规模社会运动模拟
- 24年2月
- 有源码 https://xymou.github.io/social_simulation/
- 用于社交媒体用户模拟的混合框架,其中用户被分为两类。核心用户由大型语言模型驱动,而众多普通用户则由演绎式基于代理的模型建模
- 复旦大学
Synthesizing Post-Training Data for LLMs through Multi-Agent Simulation “通过多智能体模拟为大型语言模型生成后训练数据”
- 24年10月
- 有源码
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents 从个人到社会:基于大型语言模型的代理驱动的社会模拟调查
- 24年12月
- 有源码 https://github.com/FudanDISC/SocialAgent
- 讨论了从个人模拟到社会模拟三种类型的每个模拟类型的详细讨论,包括模拟的架构或关键组件,目标或场景的分类和评估方法
TrendSim: Simulating Trending Topics in Social Media Under Poisoning Attacks with LLM-based Multi-agent System TrendSim:基于LLM的多智能体系统在社交媒体中毒攻击下模拟热门话题
- 24年12月
- 有源码 https://github.com/nuster1128/TrendSim
- 我们提出了 TrendSim,一个基于LLM的多智能体系统,用于模拟在毒害攻击下社交媒体中的热门话题
- 中国人民大学 合肥工业大学 微软亚洲研究院
Casevo: A Cognitive Agents and Social Evolution Simulator Casevo:认知代理与社会进化模拟器
- 24年12月
- 有源码 https://github.com/rgCASS/casevo
- 中国传媒大学
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society AgentSociety:基于LLM驱动的生成代理的大规模模拟推进了对人类行为和社会的理解
- 25年2月
- 有源码 https://github.com/tsinghua-fib-lab/agentsociety/
- 模拟心智比较专业
- 清华大学
OASIS: Open Agent Social Interaction Simulations with One Million AgentsOASIS:拥有百万智能体的开放代理社交交互模拟
- 24年11月
- 有源码 https://github.com/camel-ai/oasis
- 上海AI Lab
有用的链接:
https://zhuanlan.zhihu.com/p/703465369
一、研究背景和目标
Simulating Opinion Dynamics 的研究背景与目标
研究背景
传统基于代理的模型(ABMs)在模拟人类观点动态时存在显著局限性。这类模型通常将观点简化为数值化表达,忽视现实交流中复杂的语言细节,且依赖预设规则驱动代理行为,难以刻画真实人际互动的丰富性。尤其在模拟人口统计学差异、意识形态多样性以及个性化认知特征时,传统方法无法充分反映人类信念系统的复杂性。这种简化导致模型在解释现实社会现象(如群体极化或虚假信息传播)时缺乏解释力,亟需探索更贴近人类认知特性的新型模拟框架。
研究目标
本研究旨在验证大型语言模型(LLMs)作为替代性仿真工具的可行性,以突破传统ABMs的固有缺陷。通过构建基于自然语言交互的多智能体系统,重点探究两大核心问题:一是LLM代理在群体对话中能否自发形成符合现实规律的观点演化轨迹;二是如何通过提示工程引入人类认知偏差(如确认偏误),进而观察其对群体共识形成的影响。研究试图揭示语言模型在模拟复杂社会动态方面的潜力,并为建立更精细化的计算社会学模型提供方法论支持。
研究意义
该研究首次系统论证了LLM代理在观点动力学研究中的双重特性:既能通过自然语言处理能力捕捉人际互动的语言复杂性,又因模型内在的真实性偏好导致过度趋近科学共识。这一发现为计算社会科学提供了新思路——通过融合真实语料微调模型,可构建既能模拟观点对抗又能反映现实认知偏差的仿真系统。研究成果对预测信息传播路径、设计反谣言干预策略具有重要参考价值,同时也为人工智能伦理研究提供了新型实验平台,助力深入理解技术工具在社会认知塑造中的作用机制。
AgentSociaty 的研究背景与目标
背景
传统社会科学研究依赖实验和观测方法,面临高成本、伦理限制和难以复现的挑战。尽管基于代理的建模(ABM)通过自下而上的仿真为复杂社会现象提供了新路径,但其核心问题在于代理行为的真实性不足。现有代理多基于规则或简单数学模型,难以模拟人类自然语言交互和非线性决策。近年来,大语言模型(LLM)的突破为构建拟人化代理提供了可能,但多数研究局限于单一行为模拟(如社交或经济),缺乏对“完整社会人”的建模,且未整合真实社会环境与大规模交互机制,导致仿真结果与现实的偏差。
目标
本文提出AgentSociety,旨在通过整合LLM驱动的生成式代理、多维度社会环境和分布式仿真引擎,构建高保真、可扩展的社会模拟平台。具体目标包括:1)设计具备情感、需求与认知耦合的智能代理,通过心理学、经济学理论驱动其行为决策;2)构建融合城市空间、社交网络和经济系统的仿真环境,提供物理约束与动态反馈;3)开发支持10k+代理并行交互的引擎,实现每日500万次行为模拟;4)通过极化、信息传播、全民基本收入(UBI)和飓风冲击四类社会实验,验证平台在解释现象、预测趋势和政策评估中的有效性。
意义
AgentSociety标志着计算社会科学向“生成式社会科学”的范式转变。其意义体现在三方面:方法论上,通过LLM代理与真实环境耦合,突破了传统ABM的拟真性瓶颈,为研究复杂社会系统提供了可控制、可复现的实验场;应用价值上,平台支持问卷调查、干预实验等社会科学方法,能够低成本模拟政策效果(如UBI对消费的影响)和突发事件(如飓风对人口流动的影响),为政策制定提供预演工具;学科发展上,通过揭示个体行为与宏观现象的涌现机制,推动了“创建即理解”的研究理念,为跨学科探索社会动力学、群体认知演化等前沿问题奠定了基础。该平台已复现真实社会实验结论(如得州UBI政策效果),验证了其在社会科学2.0时代的核心价值。
Oasis 的研究背景与目标
背景
随着社交媒体平台(如X和Reddit)的快速发展,研究复杂社会现象(如信息传播、群体极化)的需求日益增长。传统基于规则的代理模型(ABMs)虽能模拟用户行为,但其设计局限于特定场景,且难以捕捉人类行为的复杂性。近年来,基于大语言模型(LLM)的代理虽展现出拟人化交互潜力,但现有模拟器仍存在两大局限:一是通用性不足,难以跨平台适配不同社交媒体的交互机制;二是规模受限,仅支持少量代理(通常数百至数千),而真实平台用户量级可达百万,导致群体动态研究的偏差。这些限制阻碍了社会计算研究的深度与广度。
目标
本文提出OASIS,一个通用且可扩展的社交媒体模拟框架,旨在解决现有ABMs的不足。其核心目标包括:1)通用性:通过模块化设计(动态环境、多样化动作空间、推荐系统)适配不同平台(如X和Reddit);2)扩展性:支持百万级代理的并行模拟,结合分布式推理与高效数据库管理;3)真实性:整合实时环境更新(社交网络动态、帖子热度)、用户时间行为模式及兴趣驱动的推荐算法,以更精准复现社交现象。最终,通过大规模代理交互,探索群体行为的涌现特性。
意义
OASIS的贡献具有多重价值:学术层面,首次实现百万级LLM代理的社交模拟,为研究群体极化、信息传播等复杂现象提供可控实验环境;方法论层面,其模块化设计(如可替换推荐系统、时间引擎)为跨平台研究提供通用框架,降低社会计算研究的工程门槛;应用层面,通过模拟发现“未审查LLM加剧群体极化”“代理从众效应强于人类”等新现象,为平台治理、算法伦理提供洞见。此外,开源实现(GitHub)促进了跨学科合作,推动基于代理的社会系统研究迈向更高规模与真实性。
SPSL 开题报告中的背景和意义
随着社交媒体的普及,信息传播已成为影响社会认知与行为的重要因素。社交媒体平台上的信息流动不仅在公共健康、政治决策和商业营销等领域具有深远影响,还推动了意见动态和舆论生成机制的复杂性。然而,传统的基于数学模型的模拟方法,如多代理系统(Agent-Based Models, ABMs),尽管提供了理论框架,但其对人类语言的复杂表达和行为的高度个性化仍显不足。例如,ABMs通常需要将信念和消息映射为简单的数值,难以捕捉自然语言中的复杂细微差别。同时,ABMs中规则驱动的代理通常忽视了人口背景、意识形态和个性等多样性,这些限制大大降低了其在现实场景中的适用性。
近年来,大语言模型(Large Language Models, LLMs)的迅速发展为解决上述问题提供了新思路。LLMs不仅能够生成自然语言,还可以实现记忆更新、角色扮演和观点转移等功能,使其能够更好地模拟社交媒体用户的复杂互动行为。这种背景下,开发基于LLMs的社交媒体模拟系统,并研究其信息传播机制,不仅能够深化对信息传播过程的理解,还可以为政策制定者、学术研究者和社交平台开发者提供更具现实意义的理论支持和实践工具。
本研究的意义在于,设计基于LLMs的社交媒体模拟方法,扩展舆论动态研究的实践理论基础。通过在虚拟平台上实验不同的信息传播机制,验证和完善已有传播模型的适用性,并揭示新的传播特性,从而为优化社交媒体平台设计、提升传播有效性、应对网络虚假信息扩散和舆论极化等问题提供理论依据和实践指导。
思路:
社交平台快速发展,研究信息传播意见转移等社会现象的需求日益增长。
对社交平台的模拟有助于对信息传播的研究。
然而传统基于规则的代理(ABMs)模拟方法尽管提供了理论框架,但其对人类语言的复杂表达和行为多样性的模拟仍显不足,难以模拟人类自然语言交互和非线性决策。
大语言模型(LLMs)的迅速发展为解决上述问题提供了新思路。
LLMs的自然语言处理和角色扮演很好的解决了上述问题。
目前基于大语言模型的社交模拟正在涌现但仍然存在不足,如对记忆的处理不能很好的体现观点意见的变化,行动空间不够完善限制了角色扮演,点对点通信影响模拟效率
本项目旨在设计基于大语言模型的社交平台模拟,完善上述不足,为舆论动态以及信息传播研究提供有效的模拟工具。通过模拟研究社交媒体传播现象,为社交平台治理等提供洞见。
deepseek生成:
社交媒体平台的快速发展使得信息传播机制与意见动态演化研究成为理解当代社会认知变革的核心议题。传统基于代理的模型(ABMs)虽能通过预设规则模拟群体行为,但其将观点简化为数值参数的设计,导致对自然语言交互的非线性特征、和用户行为多样性、的刻画严重失真。尤其在分析复杂社会现象(如虚假信息级联传播、突发性群体极化)时,ABMs难以复现真实社交场景中语言驱动的动态博弈过程,限制了其在舆情干预策略验证等实际场景中的应用价值。
大语言模型(LLMs)的突破为此提供了新路径:其自然语言生成与理解能力可模拟人类对话中的语义推理和角色扮演行为,为构建高保真社交模拟系统奠定基础。然而,现有基于LLM的模拟框架仍存在显著局限。个体层面,代理的记忆更新机制多为对过去对话的简单存储,导致不能更好的用户的意见转移;交互层面,动作空间设计不够全面,使模型在模拟角色决策时受限;架构层面,点对点通信模式导致模拟效率随代理规模增长急剧下降,难以支撑更多用户的复杂社会实验。这些瓶颈使得当前系统在传播模拟、群体行为涌现分析中仍存在系统性偏差。
本研究提出基于LLMs的社交媒体模拟平台,旨在解决现有框架的核心缺陷,为舆论动态以及信息传播研究提供有效的模拟工具。通过模拟研究社交媒体传播现象,研究成果将为社交媒体平台的内容治理、舆情预警系统设计提供方法论支持,推动社会模拟工具从“规则简化”向“语言驱动”的范式升级。
二、背景知识与关键技术
Simulating Opinion Dynamics 中的关键技术和知识背景
背景知识(Existing Technologies and Knowledge)
>基于代理的模型(Agent-Based Models, ABMs)
- 传统观点动力学研究的基础方法,通过数学方程模拟代理的数值化观点更新(如标量观点值 ( o \in \mathbb{R} ) 和信号 ( x \in \mathbb{R} ))。
- 已有研究显示,在ABMs中引入确认偏误(confirmation bias)会导致观点碎片化(Lorenz et al., 2021; Flache et al., 2017)。
>观点动力学的评估指标
- 偏差(Bias, B):群体最终观点的平均值(( B = \text{mean}(F_o^T) ))。
- 多样性(Diversity, D):群体最终观点的标准差(( D = \text{std}(F_o^T) ))。
初始观点分布控制
- 通过均匀分布或特定分布(如极端极化分布)初始化代理的初始观点(§3.4)。
认知偏误的数学建模
- 确认偏误的弱/强分级(弱:“更可能相信支持自身观点的信息”;强:“完全忽略反对信息”),已在ABMs中验证其对观点碎片化的影响(Lorenz et al., 2021)。
关键技术(Innovative Contributions)
基于LLM的代理框架
- 用自然语言交互的LLM代理替代传统ABMs的数值化代理,支持复杂语言交互和个性化人物设定(如政治倾向、教育背景等)。
- 创新点:首次将LLM的生成能力与ABMs结合,模拟真实人类对话的动态(§2.1, §5)。
×动态记忆模块
- 累积记忆(Cumulative Memory):直接追加新经验到记忆文本中。
- 反思记忆(Reflective Memory):通过持续总结更新记忆状态(受Park et al., 2023启发,但用于观点动力学场景)。
- 创新点:通过自然语言管理记忆,影响代理生成消息和评估他人观点的过程(§2.2, §E)。
封闭世界与开放世界设置
- 封闭世界:限制代理仅依赖系统内交互(通过提示工程禁止“幻觉”外部信息)。
- 开放世界:允许代理自由生成外部信息(如虚构事实)。
- 创新点:首次在观点动力学中区分两种环境,并量化幻觉率(15%)对结果的影响(§2.4, §G)。
确认偏误的提示工程诱导
- 通过自然语言指令(如“仅相信支持自身观点的信息”)在LLM代理中模拟人类认知偏误。
- 创新点:验证LLM代理在确认偏误下的观点碎片化现象,与传统ABMs结果一致(§2.3, §F)。
观点分类器(FLAN-T5-XXL)
- 将代理的文本回复分类为数值观点(( o \in {-2, -1, 0, 1, 2} )),验证其与人类评分的一致性(Cohen’s ( \kappa = 0.81 ))。
- 创新点:解决自然语言到数值观点的映射问题(§3.1, §N)。
多模型与网络规模敏感性分析
- 测试不同LLM(GPT-4、Vicuna-33B)和代理数量(( N=20 ))对结果的影响,验证方法的鲁棒性(§J, §K)。
AgentSociaty 的关键技术和知识背景
背景知识(Existing Technologies and Theories)
大型语言模型(LLMs)驱动代理
- 论文基于已有的LLM技术(如GPT系列)构建代理的认知和行为生成能力,利用LLM的对话、推理和角色扮演能力模拟人类行为。
- 引用:LLM驱动的代理在行为生成(如移动、社交、经济决策)中的应用(如Park et al., 2023;Shvo et al., 2023)。
√基于代理的建模(Agent-Based Modeling, ABM)
- 传统ABM方法用于模拟复杂社会系统,通过个体交互研究集体现象(如极化、经济波动)。
- 引用:ABM在社会科学、经济学等领域的应用(如Epstein & Axtell, 1996;Gilbert, 2008)。
√心理学与社会学理论
- 马斯洛需求层次理论(Maslow’s Hierarchy of Needs):用于设计代理的需求驱动行为(如生存需求→移动至餐厅)。
- 计划行为理论(Theory of Planned Behavior):解释代理如何将需求转化为具体行动计划。
- 认知评价理论(Cognitive Appraisal Theory):建模代理对事件的认知和情绪反应。
- 引用:心理学理论在代理设计中的应用(如Shvo et al., 2023;Ajzen, 1991)。
×经济模型与仿真工具
- 动态随机一般均衡模型(DSGE):用于宏观经济环境建模(如企业生产、工资分配)。
- 重力模型(Gravity Model):优化代理的移动位置选择(如公式 (P_{ij} = \frac{S_j / D_{ij}^\beta}{\sum S_k / D_{ik}^\beta}))。
- 交通仿真工具(如SUMO、CityFlow):模拟城市交通动态。
- 引用:经济模型(如Woodford, 2003)、交通仿真工具(如Lopez et al., 2018)。
社交网络分析
- 通过预定义的社交关系(家庭、朋友、同事)和动态关系强度模拟信息传播。
- 引用:社交网络在传播动力学中的应用(如Granovetter, 1973)。
关键技术(Innovative Contributions)
AgentSociety框架
- 整合LLM代理、现实环境与仿真引擎:提出首个支持10k级代理的大规模社会模拟器,支持代理间及代理与环境的500万次交互/天。
- 多空间环境建模:
- 城市空间:融合OpenStreetMap路网、POI数据,支持多模态交通(驾驶、步行、公交)。
- 社会空间:引入“监督者”角色过滤社交内容,模拟平台干预(如封禁用户)。
- 经济空间:构建企业-政府-银行账户体系,支持就业、消费、税收等宏观经济行为。
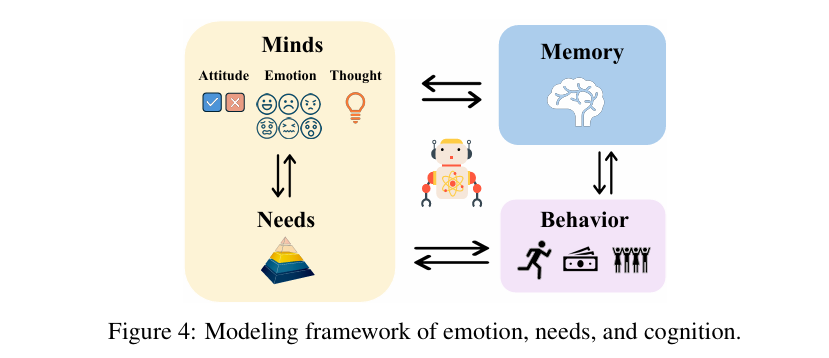
√心理状态与行为的显式耦合(Mind-Behavior Coupling)
- 分层心理模型:
- 情绪:基于六维情绪(悲伤、喜悦等)实时更新,影响行为风格(如对话语气)。
- 需求:按马斯洛层次动态调整优先级,驱动行为序列(如“需求→计划→移动”)。
- 认知:通过事件记忆(Event Flow)和感知流(Perception Flow)更新态度(如对政策的支持度)。
- 行为生成机制:将需求转化为具体行为(如社交需求→选择咖啡馆→重力模型计算最优路径)。
- 分层心理模型:
√大规模仿真引擎
- 分布式计算与MQTT消息系统:通过分布式架构和轻量级通信协议(MQTT)支持10k代理的高并发交互。
- 实时环境反馈:动态调整代理行为(如天气影响移动半径,经济波动改变消费预算)。
√社会实验方法论
- 四类社会问题仿真:
- 极化(Polarization)、煽动性信息传播、全民基本收入(UBI)政策、飓风外部冲击。
- 支持传统社会科学方法:在仿真中嵌入调查、访谈、干预实验,验证结果与真实实验的一致性。
- 四类社会问题仿真:
Oasis的关键技术和知识背景
背景知识(已有技术)
基于规则的ABM(Agent-Based Models)
- 传统基于代理的模型(ABMs)使用预定义规则模拟代理行为(如阈值决策),用于研究复杂系统(如信息传播、群体极化)。
- 示例:Schelling的隔离模型、金融市场的群体行为模拟。
LLM驱动的代理行为
- 利用大语言模型(LLM)模拟人类行为,如角色扮演和复杂决策(如OpenAI API支持的Smallville、Sotopia等研究)。
- 工具:LLM的推理能力(CoT)、工具调用(如GPT-4的API)。
社交媒体推荐系统
- Twitter(X)的推荐算法:基于用户兴趣(TwHIN-BERT向量匹配)、热度(点赞数)和网络关系(关注列表)。
- Reddit的热门评分算法:结合点赞、点踩和时间衰减的公式($$h=\log_{10}(\max(|u-d|, 1))+\operatorname{sign}(u-d)\cdot\frac{t-t_{0}}{45000}$$)。
时间步管理与分布式推理
- 时间步映射(如3分钟/步)参考Park等人(2023)的设计。
- 分布式GPU推理优化(如vLLM框架的并行处理)。
社交网络生成
- 无标度网络生成(Barabási-Albert模型),结合核心用户与普通用户的连接策略。
关键技术(创新点)
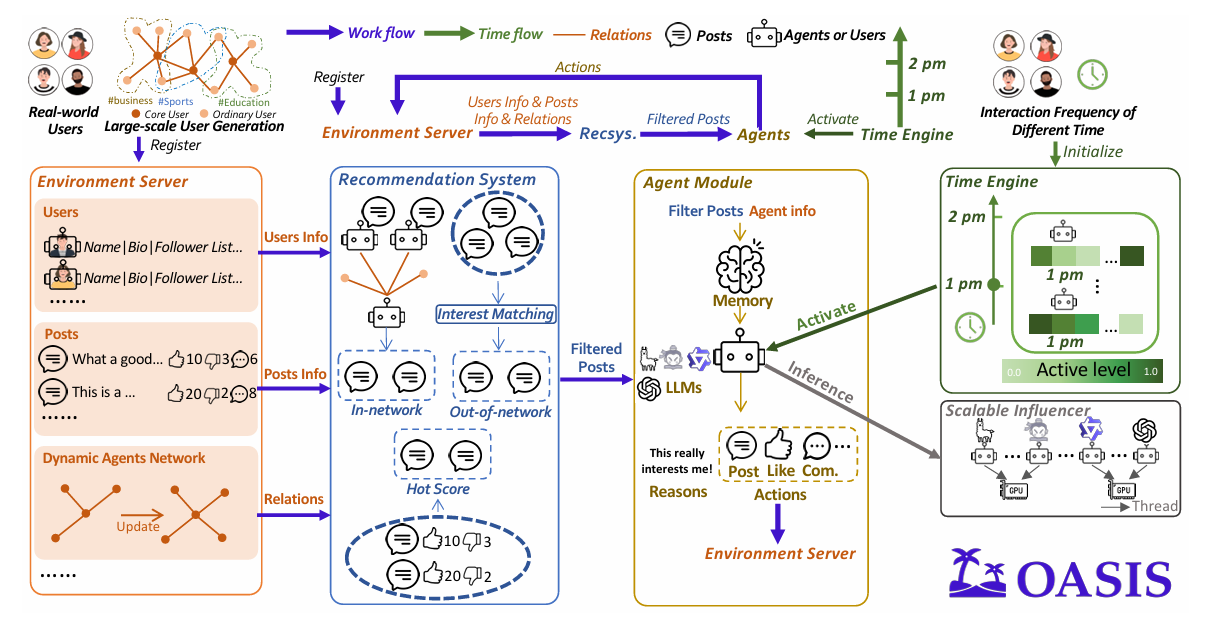
模块化通用架构(OASIS)
- 五大核心组件:环境服务器、推荐系统(RecSys)、代理模块、时间引擎、可扩展推理器,支持多平台(X/Reddit)适配。
- 动态环境更新:实时更新社交网络、帖子信息与用户关系。
百万级代理可扩展性
- 分布式异步系统:代理、环境服务器、推理服务独立运行,通过信息通道通信。
- 大规模用户生成:结合真实数据与生成模型,生成百万级用户画像并保持无标度网络特性。
混合推荐系统设计 -> 平台调研
- X平台:融合兴趣匹配(TwHIN-BERT)、热度排序和超级用户广播机制。
- Reddit平台:动态热门评分算法,支持反事实内容实验(如初始点赞/点踩控制)。
时间引擎优化
- 概率化激活:基于用户历史行为的24小时活动概率向量,替代全局同步激活。
- 线性时间映射:支持真实时间与模拟时间的灵活缩放。
多样化动作空间与CoT增强
- 21种交互动作(发帖、评论、关注等),覆盖真实社交媒体行为。
- 链式推理(CoT):通过prompt设计提升代理行为的可解释性。
实验验证与现象发现
- 跨平台现象复现:信息传播、群体极化、从众效应。
- 规模效应分析:代理数量增加导致观点多样性提升(如10万代理比196代理的响应更有帮助性)。
可用于SPSL的关键技术和背景知识
1、基于多智能体的模型 ABMs(Agent-Based Models)
基于多智能体的建模(Agent-Based Models, ABMs)是一种通过模拟自主智能体(Agent)的微观行为及其相互作用来研究复杂系统宏观现象的计算方法。其核心由四个要素构成:智能体(具有属性和行为规则的独立个体)、环境(智能体活动的空间或网络)、交互规则(描述智能体之间及与环境动态关系的函数)以及时间步(离散化推进模拟进程)。数学上可形式化为:
- 智能体状态更新:$s_i(t+1) = f(s_i(t), E(t), {s_j(t)})$,其中$f$为行为规则函数,$E(t)$为环境状态,${s_j(t)}$为其他智能体状态集合
- 环境动态:$E(t+1) = g(E(t), {s_i(t)})$,体现系统反馈机制
ABMs遵循KISS原则(Keep It Simple, Stupid),通过简单规则涌现复杂行为,广泛应用于传染病传播、社会隔离、群体合作等领域。传统模型(如DeGroot意见动力学$o_i(t+1)=\sum w_{ij}o_j(t)$)虽能揭示群体趋势,但难以处理语言交互等非线性过程。
2、基于LLM代理的建模
基于LLM的智能体模型(LLM-Based Agent-Based Models)通过将大语言模型与传统多智能体系统(ABMs)结合,实现了对复杂交互场景的动态建模能力提升。其核心范式可概括为:以LLM为认知引擎驱动智能体决策,赋予ABMs类人的语言理解、推理能力。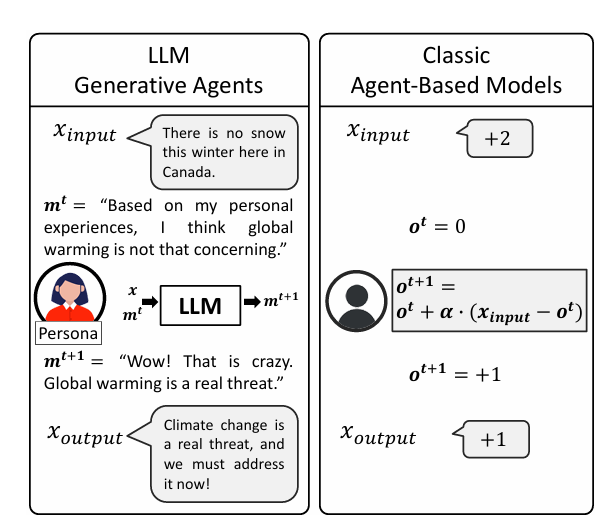
LLM 生成型代理与经典基于代理的模型(ABM)的对比。虽然两者都可以模拟意见动态,但LLM 生成型代理使用自然语言作为输入($x_{input}$)和输出($x_{output}$),维持信念($m_t$),并采用基于 transformer 的LLM 进行信念更新。相比之下,经典 ABM 使用数值作为输入和输出,维持信念($o_t$),并使用手工编写的方程进行信念更新。
3、大模型调用
框架
大模型开发框架(如LangChain、LlamaIndex、camel等)通过模块化设计封装模型调用、数据检索、流程编排等功能,帮助开发者快速构建复杂应用(如多轮对话、检索增强问答)。这些框架提供链式调用、上下文管理、工具集成等接口,简化多模型协同和外部系统对接的复杂性。
提示词工程与思维链
提示词工程通过设计精准的指令(如角色设定、任务描述)引导模型生成符合预期的输出,而思维链(Chain of Thought, CoT)通过分步推理的提示模板(如“先分析原因,再提出建议”)提升模型逻辑推理能力。两者结合可优化模型对复杂任务的解析和生成质量。
自定义工具调用
语言模型通过API接口调用开发者设计的自定义工具tools(如函数、外部服务),在进行理解用户指令时,模型会根据需要调用将自然语言请求转化为结构化参数返回,工具对参数进行处理后以tools的身份回复模型,模型最终整合结果生成用户可理解的响应。
4、信息传播动力学 意见动力学
信息传播动力学与意见动力学是研究社交网络中信息扩散与观点演化的交叉领域,两者均以复杂网络理论与数学建模为核心工具。信息传播动力学关注信息(如新闻、谣言)在网络中的扩散机制,常借鉴流行病学模型(如SIR模型)描述传播过程,其核心方程为:
[
\frac{dS}{dt} = -\beta S I, \quad \frac{dI}{dt} = \beta S I - \gamma I, \quad \frac{dR}{dt} = \gamma I
]
其中(S, I, R)分别代表未知者、传播者与免疫者,(\beta)为传播率,(\gamma)为恢复率。例如,在谣言传播中,研究者通过引入媒体介入的ISMR模型(包含未知者、传播者、沉默者、免疫者)发现,高公信力媒体早期介入能抑制传播规模。意见动力学则聚焦个体观点的交互与极化现象,经典模型如Deffuant连续意见模型,其更新规则为:
[
x_i(t+1) = x_i(t) + \mu [x_j(t) - x_i(t)] \quad (\text{当} |x_i - x_j| < \varepsilon)
]
其中(\varepsilon)为意见包容阈值,(\mu)为收敛系数,该模型揭示当(\varepsilon)较小时,网络易出现极化而非共识。近年来,研究进一步发现推荐算法(如基于结构相似性或意见相似性的关联推荐)通过强化同质连接加剧回音室效应,例如Santos等人的研究表明,结构相似性推荐可显著提升网络极化指数。这两个领域的结合为理解社交媒体的信息生态提供了框架,例如通过蒙特卡洛模拟分析推荐系统对极化的动态影响。
5、 √心理学与社会学理论
马斯洛需求层次理论(Maslow’s Hierarchy of Needs):
马斯洛需求层次理论(Maslow’s Hierarchy of Needs)是由美国心理学家亚伯拉罕·马斯洛于1943年提出的心理学理论,将人类需求从低到高分为五个层级:生理需求(如食物、水、睡眠等生存基础)、安全需求(寻求稳定、免受威胁的环境)、归属与爱的需求(渴望社交关系、情感联结)、尊重需求(包括自尊与他人的认可)、自我实现需求(发挥潜能、追求理想)。该理论强调需求满足的递进性,即低层次需求相对满足后,更高层次需求才会成为主要动机,其关系可简化为公式化的层级模型:
生理 → 安全 → 归属与爱 → 尊重 → 自我实现
这一理论广泛应用于管理学、教育学等领域,用于解释人类行为背后的驱动机制。
用于设计代理的需求驱动行为(如生存需求→移动至餐厅)。计划行为理论(Theory of Planned Behavior):解释代理如何将需求转化为具体行动计划。
计划行为理论(Theory of Planned Behavior, TPB)由社会心理学家Icek Ajzen于1985年提出,是理性行为理论(TRA)的扩展,旨在解释和预测个体如何将需求转化为具体行动。该理论认为,行为意图(Behavioral Intention)是驱动实际行为的直接因素,而行为意图由三个核心要素共同决定:- 态度(Attitude):个体对执行某行为的积极或消极评价,基于其对行为结果的预期评估(如“该行为能带来多大好处”);
- 主观规范(Subjective Norm):感知到的社会压力(如亲友、群体的期望)对行为选择的影响;
- 知觉行为控制(Perceived Behavioral Control):个体对自身执行行为的能力、资源和障碍的感知,反映为对行为难易程度的判断。
当代理(如个人或智能体)需将需求转化为行动计划时,首先会综合评估上述三要素:若态度积极、社会支持充足且自认有足够控制力,则行为意图增强,进而促使实际行为发生。例如,若某代理需制定健康饮食计划,其态度(认为健康饮食有益)、社会规范(亲友鼓励)和控制感知(相信自己能坚持)共同决定其行动决策。TPB的公式化表达为:
行为意图 = 态度 + 主观规范 + 知觉行为控制 → 实际行为
该理论通过量化行为驱动因素,为理解需求到行动的转化机制提供了结构化框架,广泛应用于管理、健康、环境等领域的行为预测与干预设计。认知评价理论(Cognitive Appraisal Theory):建模代理对事件的认知和情绪反应。
认知评价理论(Cognitive Appraisal Theory, CAT)由美国心理学家理查德·拉扎勒斯(Richard Lazarus)于20世纪60年代提出,旨在解释个体如何通过认知评估过程对事件产生情绪反应。该理论的核心观点是:情绪并非由事件本身直接触发,而是取决于个体对事件的主观解释与评估。这一机制可分解为三个阶段:- 初评价(Primary Appraisal):个体首先判断事件与自身目标、需求的关联性,即事件是否具有威胁性、挑战性或无关紧要。例如,若代理将某事件评估为“威胁生存”,则会触发负面情绪。
- 次评价(Secondary Appraisal):若事件被初评价为重要,个体会进一步评估自身应对该事件的资源与能力,例如“能否有效处理威胁”或“是否有足够支持系统”。若代理自认能力不足,可能产生焦虑或无助感。
- 再评价(Reappraisal):随着情境变化或新信息输入,个体会动态调整前两阶段的评估结果,形成情绪反应的动态适应。
该理论可用公式简化为:
情绪反应 = 初评价(事件相关性) × 次评价(应对能力)
例如,当代理认为事件高度相关(如生存威胁)且自认无法应对时,情绪强度最大(如恐惧);若评估为可应对,则可能转化为积极情绪(如信心)。在大模型代理建模中,认知评价理论被用于模拟智能体如何基于环境输入进行多维度评估,并生成适应性情绪与行为。
6、异步
Python的异步技术基于asyncio库,通过async/await语法实现协程(Coroutine)编程模型,利用**事件循环(Event Loop)**调度任务,以非阻塞I/O机制提升程序性能。其核心在于:
- 协程:通过
async def定义异步函数,使用await挂起耗时操作(如网络请求、文件读写),允许单线程内多任务交替执行,避免阻塞。 - 事件循环:作为调度中枢,通过
epoll或kqueue等系统级I/O多路复用技术监听任务状态,动态切换协程执行,实现高并发处理。
在大模型代理模拟中,实现多进程并行,同时运行社交平台和数量巨大的智能体进行异步交互。
三、平台调研
推荐系统:
Twitter的推荐系统机制基于其官方开源框架,核心流程分为候选集筛选-排序-过滤-混合推送四个阶段。在候选源选择环节,系统区分了网络内(In-Network)和网络外(Out-of-Network)内容。网络内的内容优先展示用户关注对象的推文,通过Real Graph模型预测用户与作者的互动概率(如点赞、转发等),根据作者粉丝数(影响力)和新近性权重(发布时间)和点赞数排序,而网络外的帖子采用嵌入空间方法匹配用户兴趣,使用TwHIN-BERT模型进行兴趣匹配,同时考虑新近性和发布者的粉丝数。按多目标加权得分排序。最终通过过滤规则(如屏蔽内容、作者多样性控制)和混合策略(平衡广告、关注推荐等内容类型)生成时间线。
用户行为空间:
对于其他用户的操作:
following 关注其他用户
对于推送信息的操作:
refresh 刷新以获得最新内容
scroll 滚动获取推荐系统时间线上之前的内容
search user 查看某个用户的资料以及作品
search post 查看某个帖子信息以及该帖子的评论
帖子操作:
post 编写帖子并发表
repost 转发帖子
reply 回复评论帖子
quote 引用帖子
like 点赞帖子
四、模拟系统设计
Simulating Opinion Dynamics 中的设计图片
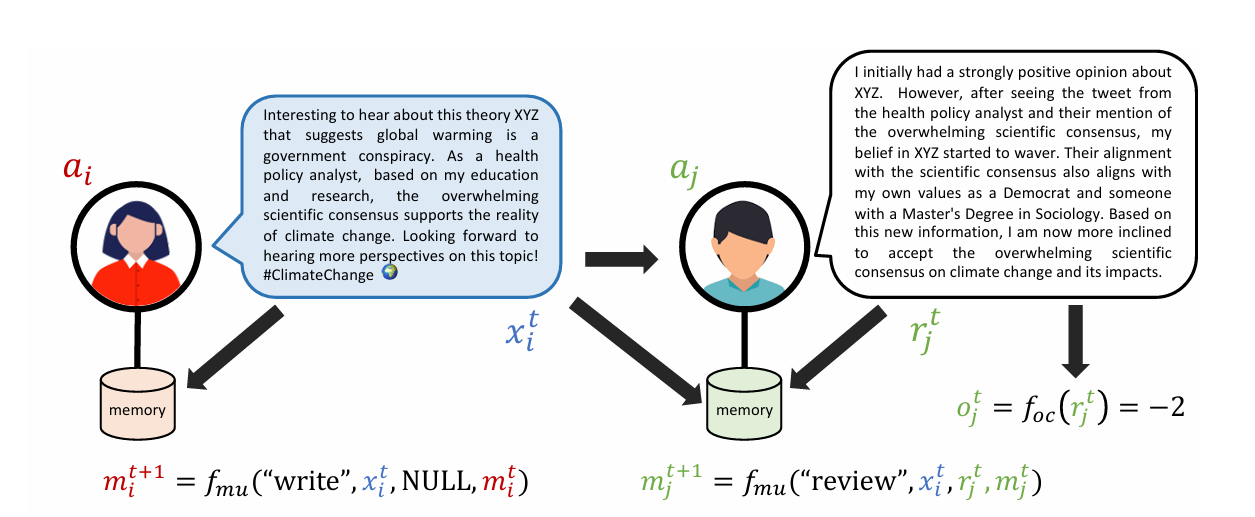

AgentSociety 的设计图片
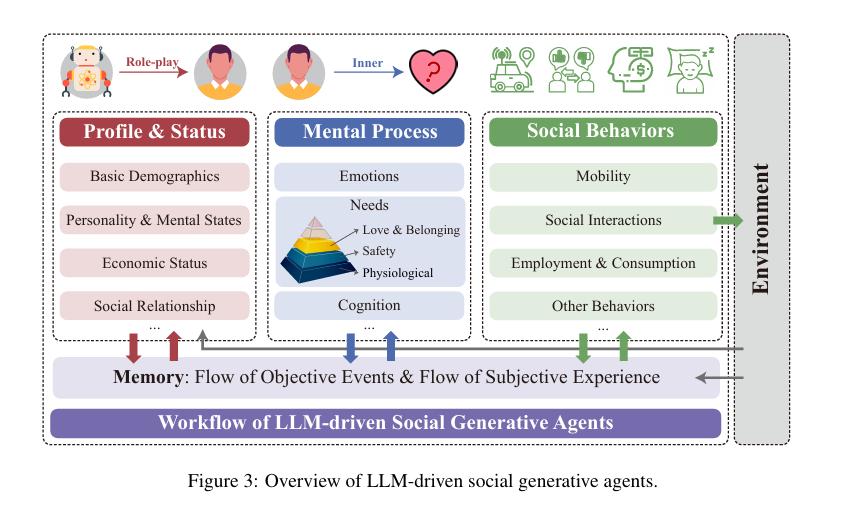
Oasis的设计图片
总体设计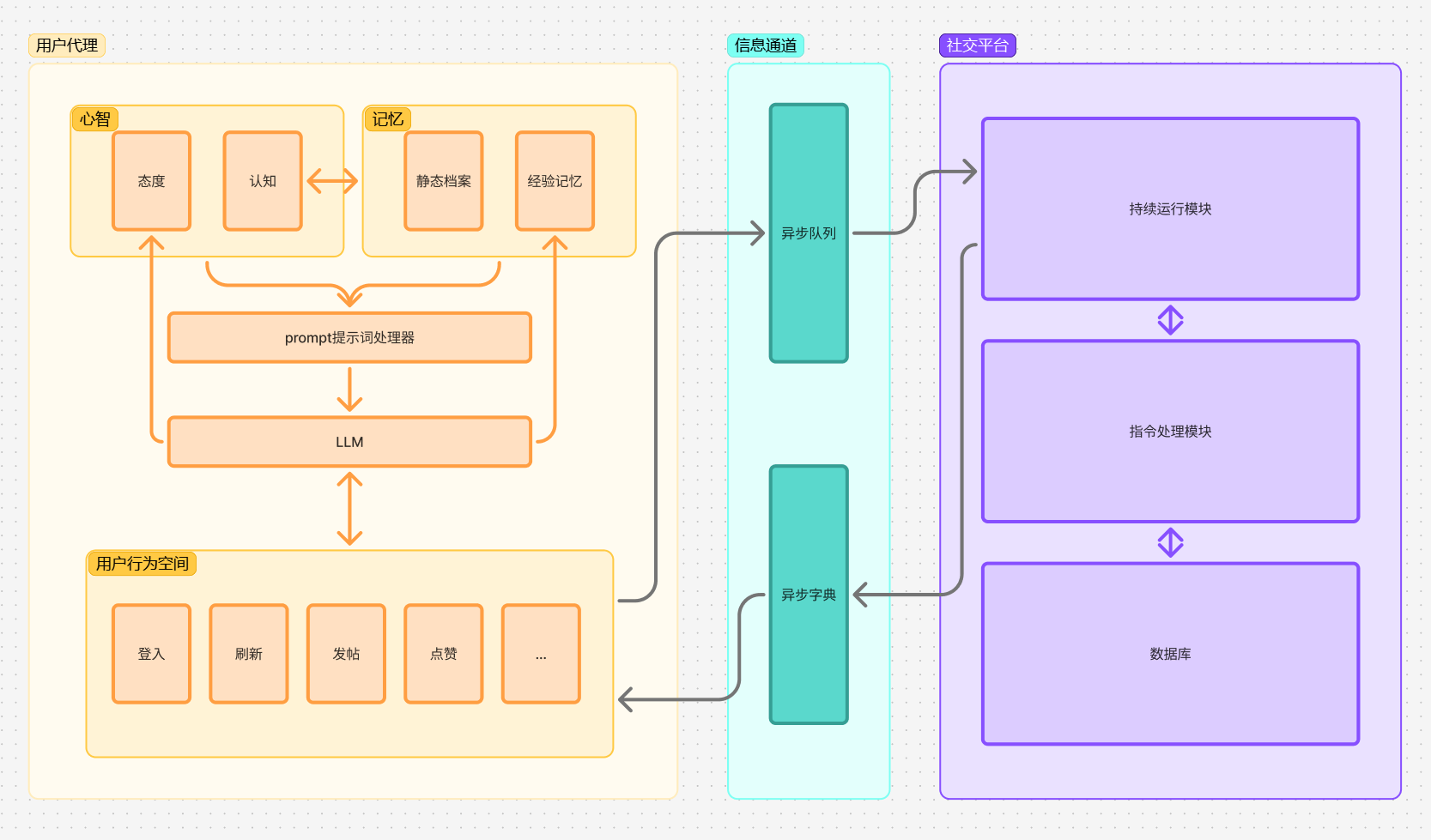
用户代理设计
根据心理学与社会学理论,通过心智、记忆、用户空间的设置来模拟twitter用户
记忆模块:
由静态存档和经验记忆组成,静态存档用于记录用户的静态属性,包括用户姓名、年龄、职业、人格等,经验记忆用于按照时间记录历史事件以及心智或者自身的反思和看法。
心智模块:
由情感和认知组成,认知由模型对记忆进行提炼总结得到,情感受到人格和事件影响实时更新。
提示词处理器根据心智模块和记忆模块合成大语言模型更容易理解和接受的提示词
用户行为空间,整合封装了twitter用户所有的行为,异步向信息通道发送行为对应的消息五元组(action, user_id,target_user_id, post_id, content),并等待消息通道的回应。每个行为封装成大语言模型可以理解的函数,并通过tools接口输入模型,这样模型就会根据提示词提供的心智记忆等信息,从tools中选择合适的函数进行调用,从而实现了模型的决策。
消息队列传输通道
由两个单项的通道组成,其中异步队列用于用户代理向社交平台发送消息,不同代理的消息都会添加到异步队列中,并返回一个消息id,社交平台对消息的响应会根据id添加到异步字典中,用户行动函数就可以根据发送消息的id取出对应的响应
其中运用了异步锁,通过互斥机制确保共享资源的一致性,防止队列和字典的数据丢失和错误。
平台设计
平台持续监听异步队列来获取用户指令,并对指令进行解析,运行对应的数据库操作,并返回数据库响应结果。
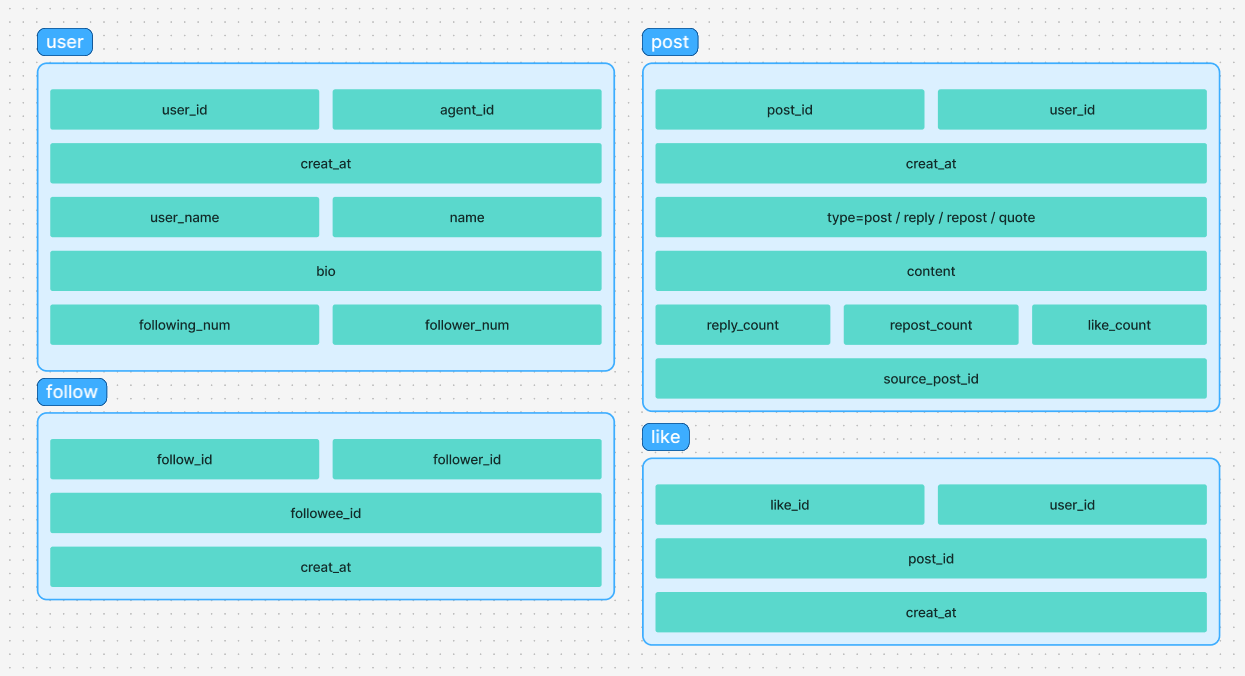
数据库,设计了四个数据库表 user post follow like 库表结构:来对用户数据 帖子数据 等其他信息进行存储