
论文阅读-1
S3: Social-network Simulation System with Large Language Model-Empowered Agents
S3: 社交网络模拟系统 大型语言模型赋能的代理
https://ar5iv.labs.arxiv.org/html/2307.14984?_immersive_translate_auto_translate=1
这个人博客里有分析好的
https://blog.csdn.net/qq_40671063/article/details/136508617
Abstract 摘要
Simulation plays a crucial role in addressing various challenges within social science. It offers extensive applications such as state prediction, phenomena explanation, and policy-making support, among others. In this work, we harness the human-like capabilities of large language models (LLMs) in sensing, reasoning, and behaving, and utilize these qualities to construct the S3 system (short for Social network Simulation System). Adhering to the widely employed agent-based simulation paradigm, we employ fine-tuning and prompt engineering techniques to ensure that the agent’s behavior closely emulates that of a genuine human within the social network. Specifically, we simulate three pivotal aspects: emotion, attitude, and interaction behaviors. By endowing the agent in the system with the ability to perceive the informational environment and emulate human actions, we observe the emergence of population-level phenomena, including the propagation of information, attitudes, and emotions. We conduct an evaluation encompassing two levels of simulation, employing real-world social network data. Encouragingly, the results demonstrate promising accuracy. This work represents an initial step in the realm of social network simulation empowered by LLM-based agents. We anticipate that our endeavors will serve as a source of inspiration for the development of simulation systems within, but not limited to, social science.
仿真在解决社会科学中的各种挑战方面发挥着至关重要的作用。
它提供广泛的应用,例如状态预测、现象解释和政策制定支持等。
在本项目中,我们控制大型语言模型(LLMs)在感知、推理和行为方面的类似人类的能力,并利用这些特性来构建 S$^3$ 系统(Social network Simulation System 的缩写)。
遵循广泛采用的基于智能体的模拟范式,我们采用微调和提示工程技术,以确保智能体的行为与社交网络中真实人类的行为密切相关。
具体来说,我们模拟了三个关键方面:情绪、态度和交互行为。
通过赋予系统中的代理感知信息环境和模拟人类行为的能力,我们观察到群体层面现象的出现,包括信息、态度和情感的传播。
我们采用真实的社交网络数据,进行包括两个级别的模拟的评估。
令人鼓舞的是,结果显示出有希望的准确性。
这项工作代表了由LLM基于代理的社交网络模拟领域的第一步。我们预计我们的努力将成为开发模拟系统的灵感源泉,但不限于社会科学。仿真比较重要,我们用了微调和提示词技术来让模型在情绪态度和交互方面模拟人类,让模型感知环境和其他模型,形成群体,研究其传播,做了两个模拟评估,效果良好
1 Introduction 介绍
The social network, comprising interconnected individuals in society, constitutes a cornerstone of the contemporary world. Diverging from mathematical analysis, computer simulation offers a fresh avenue to comprehend the formation and evolution of social networks. This serves as a fundamental tool for social scientists. Notably, in 1996, there was already a book titled Social Science Microsimulation troitzsch1996social providing valuable insights about simulation from the perspective of social science. Social simulation encompasses a wide range of domains, encompassing both individual and population social activities. At the heart of social simulation lie two perspectives gilbert2005simulation: 1) the dynamic feedback or interaction among individuals, and 2) the states of the population, either as a collective whole or as distinct groups. By simulating social activities, researchers and practitioners can predict the future evolution of individual and population states. In addition, they facilitate experimental environments through interventions. Social simulation can be implemented in two forms: microlevel simulation chopard1998cellular; park2023generative and macrolevel simulation kolesar1975simulation; meadows1974dynamics; forrester1993system; marsh1978using. In macrolevel simulation, also known as system-based simulation, researchers model the dynamics of the system using equations that elucidate the changing status of the population. Conversely, microlevel simulation, or agent-based simulation, involves researchers employing either human-crafted rules or parameterized models to depict the behavior of individuals (referred to as agents) who interact with others. Recently, with the exponential growth of the Internet, online social networks have emerged as the principal platform for societal activities. Users engage in various interactive behaviors such as chatting, posting, and sharing content. Consequently, the study of social networks has become a central research focus within the realm of social science, thereby emphasizing the criticality of simulation in this domain.
社交网络由社会中相互关联的个体组成,构成了当代世界的基石。
与数学分析不同,计算机模拟为理解社交网络的形成和演变提供了一条新的途径。
这是社会科学家的基本工具。
值得注意的是,在 1996 年,已经有一本名为《社会科学微观模拟》的书从社会科学的角度提供了有关模拟的宝贵见解。
社会模拟涵盖广泛的领域,包括个人和群体社会活动。
社会模拟的核心在于两个视角: 1) 个体之间的动态反馈或互动,以及 2) 人口的状态,无论是作为一个集体整体还是作为不同的群体。
通过模拟社会活动,研究人员和从业者可以预测个体和种群状态的未来演变。
此外,它们还通过干预促进实验环境。
==社会模拟可以以两种形式实现:微观模拟和宏观模拟。==
在宏观模拟(也称为基于系统的模拟)中,研究人员使用阐明种群状态变化的方程式对系统的动力学进行建模。
相反,微观模拟或基于智能体的模拟涉及研究人员采用人工制定的规则或参数化模型来描述与他人交互的个人(称为智能体)的行为。
最近,随着互联网的指数级增长,在线社交网络已成为社会活动的主要平台。
用户参与各种互动行为,例如聊天、发帖和共享内容。
因此,社交网络的研究已成为社会科学领域的中心研究重点,从而强调了模拟在该领域的重要性。社会模拟非常重要,分为微观(设置个体行为)和宏观(群体状态变换方程)
Large language models (LLMs) brown2020language; openai2023gpt4; chowdhery2022palm; anil2023palm; touvron2023llama; zeng2022glm are the recent advancement in the field of deep learning, characterized by the utilization of an extensive array of neural layers. These models undergo training on vast textual corpora, acquiring a remarkable fundamental capacity to comprehend, generate, and manipulate human language.
大型语言模型 (LLMs)是深度学习领域的最新进展,其特点是利用了广泛的神经层阵列。
这些模型在庞大的文本语料库上接受训练,获得了理解、生成和纵人类语言的非凡基本能力。
Given their impressive prowess in text comprehension, which closely approximates human-level performance, LLMs have emerged as a particularly auspicious avenue of research for approaching general artificial intelligence. Consequently, researchers aher2023using; horton2023large; hamalainen2023evaluating; park2023generative leverage LLMs as agent-like entities for simulating human-like behavior, capitalizing on three fundamental capabilities. First and foremost, LLMs possess the ability to perceive and apprehend the world, albeit restricted to environments that can be adequately described in textual form. Secondly, LLMs are capable of devising and organizing task schedules by leveraging reasoning techniques that incorporate both task requirements and the attendant rewards. Throughout this process, LLMs effectively maintain and update a memory inventory, employing appropriately guided prompts rooted in human-like reasoning patterns. Lastly, LLMs exhibit the capacity to generate texts that bear a striking resemblance to human-produced language. These textual outputs can influence the environment and interact with other agents. Consequently, it holds significant promise to adopt an agent-based simulation paradigm that harnesses LLMs to simulate each user within a social network, thereby capturing their respective behaviors and the intricate interplay among users.
鉴于他们在文本理解方面的令人印象深刻的实力,这与人类水平的表现非常接近,LLMs已成为接近一般人工智能的特别优秀的研究途径。
因此,研究人员生成式利用 LLMs 作为类似代理的实体来模拟类人行为,利用三个基本功能。
首先,LLMs拥有 ==感知和理解世界的能力==,尽管仅限于可以用文本形式充分描述的环境。
其次,LLMs能够通过利用包含任务要求和参与奖励的推理技术来设计和组织任务时间表。
在整个过程中,LLMs有效地维护和更新内存清单,采用植根于类似人类推理模式的适当引导提示。
最后,LLMs展示生成与人类语言惊人相似的文本的能力。
这些文本输出可以影响环境并与其他代理交互。
因此,采用基于代理的模拟范式具有重大前景,该范式利用LLMs来模拟社交网络中的每个用户,从而捕获他们各自的行为和用户之间错综复杂的相互作用。
In this study, we present the Social-network Simulation System (S3), which employs LLM-empowered agents to simulate users within a social network effectively. Initially, we establish an environment using real-world social network data. To ensure the authenticity of this environment, we propose a user-demographic inference module that combines prompt engineering with prompt tuning, to infer user demographics such as age, gender, and occupation. Within the constructed environment, users have the ability to observe content from individuals they follow, thereby influencing their own attitudes, emotions, and subsequent behaviors. Users can forward content, create new content, or remain inactive. Hence, at the individual level, we employ prompt engineering and prompt tuning methodologies to simulate attitudes, emotions, and behaviors. Notably, this simulation considers both demographics and memory of historically-posted content. At the population level, the accumulation of individual behaviors, including content generation and forwarding, alongside the evolving internal states of attitudes and emotions, leads to the emergence of collective behavior. This behavior encompasses the propagation of information, attitudes, and emotions.
在这项研究中,我们提出了社交网络模拟系统 (S$^3$),它采用LLM授权代理来有效地模拟社交网络中的用户。
最初,我们使用真实的社交网络数据建立一个环境。
为了确保这个环境的真实性,我们提出了一个用户人口统计推理模块,该模块将提示工程与提示调整相结合,以推断年龄、性别和职业等用户人口统计数据。
在构建的环境中,用户能够观察他们关注的个人的内容,从而影响他们自己的态度、情绪和后续行为。
用户可以转发内容、创建新内容或保持非活动状态。
因此,在个人层面,我们采用快速工程和快速调整方法来模拟态度、情绪和行为。
值得注意的是,此模拟同时考虑了人口统计和历史发布内容的内存。
在人口层面,个体行为的积累,包括内容生成和转发,以及态度和情感的内部状态的演变,导致了集体行为的出现。
这种行为包括信息、态度和情感的传播。
To assess the efficacy of the proposed S3 system, we have chosen two exemplary scenarios, namely, gender discrimination and nuclear energy. With respect to gender discrimination, our objective is to simulate user responses to online content associated with this issue, while closely observing the dissemination patterns of related information and evolving public sentiment. Regarding nuclear energy, our aim is to simulate user reactions to online content pertaining to power policies. In addition, we aim to simulate the contentious and conflicting interactions between two opposing population groups. To evaluate the precision of our simulations, we employ metrics that measure accuracy at both the individual and population levels. This work’s main contributions can be summarized as follows.
为了评估拟议的 S$^3$ 系统的有效性,我们选择了两个示例情景,即性别歧视和核能。
在性别歧视方面,我们的目标是模拟用户对与此问题相关的在线内容的反应,同时密切观察相关信息的传播模式和不断变化的公众情绪。
关于核能,我们的目标是模拟用户对与电力政策相关的在线内容的反应。
此外,我们的目标是模拟两个对立群体之间的有争议和冲突的互动。
为了评估模拟的精度,我们采用了衡量个体和群体水平准确性的指标。
这项工作的主要贡献可以总结如下。
- We take the pioneering step of simulating social networks with large language models (LLMs), which follows the agent-based simulation paradigm, and empowers the agents with the latest advances.
我们迈出了使用大型语言模型 (LLMs) 模拟社交网络的开创性一步,它遵循基于智能体的模拟范式,并为智能体提供最新的进展。
- We develop a simulation system that supports both individual-level and population-level simulations, which can learn from the collected real social network data, and simulate future states.
我们开发了一个模拟系统,该系统支持个体水平和种群水平的模拟,可以从收集到的真实社交网络数据中学习,并模拟未来状态。
- We systematically conduct the evaluation, and the results show that the simulation system with LLM-empowered agents can achieve considerable accuracy in multiple metrics. Consequently, our system introduces a novel simulation paradigm in social science research, offering extensive support for scientific investigations and real-world applications.
我们系统地进行了评估,结果表明,带有 LLM 主导的 智能体的仿真系统在多个指标上都能达到相当的准确性。
因此,我们的系统在社会科学研究中引入了一种新的模拟范式,为科学调查和实际应用提供了广泛的支持。
To provide a comprehensive understanding of the current research landscape, we begin by reviewing relevant works in Section 2. Subsequently, we proceed to introduce the simulation system in Section 3, followed by a detailed exposition of the methodology and implementation in Section 4. In Section 5, we engage in discussions and analyze open challenges associated with related research and applications. Finally, we conclude our work in Section 6.
为了全面了解当前的研究形势,我们首先回顾了第 2 节中的相关工作。随后,我们继续在第 3 节中介绍仿真系统,然后在第 4 节中详细阐述了该方法和实现。在第 5 节中,我们参与讨论并分析与相关研究和应用相关的开放挑战。最后,我们在第 6 节中结束我们的工作。
2 Related Works 相关作品
In this section, we discuss two areas close to this work, social simulation and large language model-based simulation.
在本节中,我们将讨论与这项工作相关的两个领域,即社交模拟和基于大型语言模型的模拟。
2.1 Social Simulation
2.1社交模拟(社会模拟)
According to bratley1987guide, “Simulation means driving a model of a system with suitable inputs and observing the corresponding outputs”. Social simulation aims to simulate various social activities, which encompass a wide range of applications gilbert2005simulation. One primary advantage of social simulation is its potential to aid social scientists in comprehending the characteristics of the social world axelrod1997advancing. This is primarily attributed to the fact that the internal mechanisms driving social behaviors are not directly observable. By employing a simulation model capable of reasonably replicating the dynamic nature of historical social behaviors, it becomes feasible to utilize the simulation tool for predicting the future of the social system. Furthermore, social simulation can serve as a training ground, particularly for economists involved in social-economic simulations spencer1984effect. In this context, the economist can assume a digital persona, namely an artificial intelligence program tasked with formulating economic policies. Moreover, social simulation can even serve as a substitute for human presence, exemplified by the emergence of digital avatars in the metaverse lee2021all. From the perspective of social science research, social simulation plays a crucial role in facilitating the development of new social science theories. It achieves this by validating theoretical assumptions and enhancing theory through the application of more precise formalizations.
根据 bratley ,“仿真意味着使用合适的输入驱动系统模型并观察相应的输出”。
社交模拟旨在模拟各种社交活动,其中包含广泛的应用。
社会模拟的一个主要优势是它有可能帮助社会科学家理解社会世界的特征。
这主要归因于驱动社会行为的内部机制无法直接观察到的事实。
通过采用能够合理复制历史社会行为动态性质的仿真模型,利用仿真工具预测社会系统的未来变得可行。
此外,社会模拟可以作为训练场,特别是对于参与社会经济模拟的经济学家。
在这种情况下,经济学家可以假设一个数字角色,即一个负责制定经济政策的人工智能程序。
此外,社交模拟甚至可以替代人类的存在,元宇宙中数字化身的出现就是例证。
从社会科学研究的角度来看,社会模拟在促进新的社会科学理论的发展中起着至关重要的作用。
它通过验证理论假设并通过应用更精确的形式化来增强理论来实现这一点。为什么需要社交模拟,社交模拟重要性
In spite of the promising applications, conducting social simulation is complex. The earliest works use discrete event-based simulation kolesar1975simulation or system dynamics meadows1974dynamics; forrester1993system; marsh1978using with a series of equations to approximate multiple variables over time that partly describe the system. These early methods primarily focused on accurately predicting the variables rather than elucidating the underlying mechanisms or causal relationships. Subsequently, drawing inspiration from the rapid development and remarkable success of simulation in other scientific domains, the utilization of agent-based simulation emerged in the field of social simulation. A notable and representative technique among these simulation methods is the employment of Cellular Automata chopard1998cellular. Initially, this approach establishes a social environment composed of numerous individuals and subsequently formulates a set of rules dictating how individuals interact with one another and update their states. Agent-based simulation can be regarded as a micro-level simulation that approximates real-world systems by describing the behavior of explicitly defined micro-level individuals. Thus, it is also referred to as microsimulation.
尽管应用前景广阔,但进行社交模拟却很复杂。
最早的作品使用基于离散事件的模拟或系统动力学使用使用一系列方程来近似随时间变化的多个变量,这些变量部分描述了系统。
这些早期方法主要侧重于准确预测变量,而不是阐明潜在机制或因果关系。
随后,从模拟在其他科学领域的快速发展和显著成功中汲取灵感,基于代理的模拟在社会模拟领域出现了。
在这些模拟方法中,一个值得注意和具有代表性的技术是 Cellular Automata (蜂窝自动机) 的使用。
最初,这种方法建立了一个由众多个体组成的社会环境,随后制定了一套规则,规定了个体如何相互交互并更新他们的状态。
基于代理的模拟可以被视为一种微观层面的模拟,它通过描述明确定义的微观层面个体的行为来接近现实世界的系统。
因此,它也被称为微观模拟。
In recent times, owing to significant advancements in machine learning and artificial intelligence, agent-based simulation has witnessed a notable transformation. This transformation is characterized by the utilization of increasingly intricate and robust agents propelled by machine learning algorithms. These agents possess the ability to dynamically perceive their surroundings and exhibit actions that closely resemble human behavior. The rapid progress in simulating individual agents has not only preserved the effectiveness of conventional simulation paradigms but has also resulted in significant improvements. This is particularly important for large language models, which are on the path towards achieving partial general artificial intelligence. Consequently, in this study, we embrace the microsimulation paradigm and employ meticulously guided and finely tuned large language models to govern the behavior of individuals within social networks.
近年来,由于机器学习和人工智能的重大进步,基于智能体的模拟发生了显着转变。
这种转变的特点是利用由机器学习算法推动的日益复杂和强大的代理。
这些代理具有动态感知周围环境并表现出与人类行为非常相似的动作的能力。
模拟单个智能体的快速进步不仅保留了传统模拟范式的有效性,而且还带来了显著的改进。
这对于大型语言模型尤其重要,因为大型语言模型正在实现部分通用人工智能。
因此,在这项研究中,我们采用了微观模拟范式,并采用精心指导和微调的大型语言模型来控制社交网络中个人的行为。
2.2 Large Language Model-based Simulation
2.2 元基于大型语言模型的模拟
Recently, relying on the strong power in understanding and generating human language, large language models such as GPT series brown2020language; openai2023gpt4, PaLM series chowdhery2022palm; anil2023palm, LLaMA touvron2023llama, GLM zeng2022glm, etc. are attracting widespread attention.
近日,依托人类语言理解和生成能力,GPT 系列等大型语言模型, PaLM 系列 GLM 等引起了广泛关注。
LLMs have exhibited exceptional capabilities in zero-shot scenarios, enabling rapid adaptation to diverse tasks across academic and industrial domains. The expansive language model aligns well with the agent-based simulation paradigm mentioned earlier, wherein the primary objective involves constructing an agent represented by a rule or program endowed with sufficient capacity to simulate real-world individuals.
LLMs在零样本场景中表现出卓越的能力,能够快速适应学术和工业领域的各种任务。
扩展语言模型与前面提到的基于代理的模拟范式非常一致,其中主要目标涉及构建由规则或程序表示的代理,该规则或程序具有足够的能力来模拟现实世界的个体。
Aher et al. aher2023using conducted a preliminary test to find that LLMs possess the capability to reproduce some classic economic, psycholinguistic, and social psychology experiments. Horton et al. horton2023large substitute human participants with LLM agents, which are given endowments, information, preferences, etc., with prompts and then simulate the economic behaviors. The results with LLM-empowered agents show qualitatively similar results to the original papers (with human experiments) samuelson1988status; charness2002understanding. Another study hamalainen2023evaluating adopts an LLM-based crowdsourcing approach by gathering feedback from LLM avatars representing actual humans, to support the research of computational social science.
Aher 进行了一项初步测试,发现LLMs具有重现一些经典经济学、心理语言学和社会心理学实验的能力。
Horton 用LLM代理替代人类参与者,代理通过提示获得禀赋、信息、偏好等,然后模拟经济行为。
使用 LLM-empowered 代理的结果显示与原始论文(通过人体实验)质量相似的结果。
另一项研究采用LLM基于众包的方法,通过收集代表真实人类的化身的反馈LLM,以支持计算社会科学的研究。
Recently, Part et al. park2023generative construct a virtual town with 25 LLM-empowered agents based on a video game environment, in which the agent can plan and schedule what to do in daily life. Although the simulation is purely based on a generative paradigm without any real-data evaluation, it provides insights that LLM can serve as a powerful tool in agent-based simulation. Each agent was assigned its own identity and distinct characteristics through prompts, facilitating communication among them. It is noteworthy that this simulation was conducted exclusively within a generative paradigm, without incorporating any real-world data for evaluation. Nevertheless, the findings offer valuable insights into LLM’s potential as a potent tool in agent-based simulations.
最近,Part 基于视频游戏环境构建了一个拥有 25 LLM个授权代理的虚拟城镇,代理可以在其中计划和安排日常生活中要做什么。
尽管该模拟完全基于生成范式,没有任何实时数据评估,但它提供的见解LLM可以作为基于智能体的模拟的强大工具。
通过提示为每个代理分配了自己的身份和独特的特征,从而促进了他们之间的交流。
值得注意的是,这种模拟完全是在生成范式中进行的,没有纳入任何真实世界的数据进行评估。
尽管如此,这些发现为 LLM作为基于智能体的模拟中的有效工具的潜力提供了有价值的见解。
3 Social Network Simulation 社交网络模拟
3.1 System Overview 系统概述
Our system is constructed within a social network framework, wherein the agent’s capabilities are augmented through the utilization of large language models. More specifically, our primary objective is to ensure that the simulation attains a significant degree of quantitative accuracy, catering to both individual-level and population-level simulations. Regarding individual-level simulation, our aim is to replicate behaviors, attitudes, and emotions by leveraging user characteristics, the informational context within social networks, and the intricate mechanisms governing user cognitive perception and decision-making. Through the utilization of agent-based simulation, we further assess the population-level dynamics by scrutinizing the performance of simulating three pivotal social phenomena: the propagation process of information, attitude, and emotion.
我们的系统是在社交网络框架内构建的,其中代理的能力通过利用大型语言模型得到增强。
更具体地说,我们的主要目标是确保模拟达到相当程度的定量准确性,同时满足个体水平和种群水平的模拟。
关于个体层面的模拟,我们的目标是通过利用用户特征、社交网络中的信息上下文以及控制用户认知感知和决策的复杂机制来复制行为、态度和情绪。
通过利用基于代理的模拟,我们通过仔细检查模拟三个关键社会现象的性能来进一步评估人口水平的动态:信息、态度和情感的传播过程。
Refer to caption
Figure 1:The overview of the social network simulation system.
图 1:社交网络模拟系统概述。
3.2 Social Network Environment 社交网络环境
In this study, our focus is directed toward two specific focal points, namely gender discrimination and nuclear energy. These particular subjects are chosen owing to their highly controversial nature, which yielded an extensive corpus of data. More specifically, our investigation regarding nuclear energy centers on examining the prevailing attitudes of the general public toward the choice between supporting nuclear energy sources or relying on fossil fuels. As for gender discrimination, our objective is to delve into the emotional experiences of individuals and populations, particularly those elicited by incidents of gender-based discrimination, such as feelings of anger. The availability of such copious amounts of data facilitates the extraction of a substantial portion of the authentic network, thereby enabling us to gain a macroscopic perspective that closely approximates reality. To conduct this analysis, we collect the real data with users, social connections, and textual posts in social media, as detailed in Table 1. This dataset provides us with the necessary resources to delve deep into the dynamics of these contentious subjects and gain valuable insights into their impact on social networks.
在这项研究中,我们的重点针对两个具体的焦点,即性别歧视和核能。
选择这些特定主题是因为它们具有高度争议的性质,从而产生了广泛的数据语料库。
更具体地说,我们对核能的调查集中在研究公众对支持核能或依赖化石燃料之间做出选择的普遍态度。
至于性别歧视,我们的目标是深入研究个人和群体的情感体验,特别是那些由基于性别的歧视事件引起的情感体验,例如愤怒的感觉。
如此大量数据的可用性有助于提取真实网络的很大一部分,从而使我们能够获得与现实非常接近的宏观视角。
为了进行此分析,我们收集了用户、社交联系和社交媒体中的文本帖子的真实数据,如表 1 所示。
该数据集为我们提供了必要的资源,以深入研究这些有争议的话题的动态,并获得有关它们对社交网络影响的宝贵见解。两个研究焦点介绍
User demographics play a pivotal role in shaping user behavior, necessitating the development of a more extensive user persona to enable the realistic and plausible simulation of their actions. However, due to the limited availability of user information obtained directly from social media, it becomes imperative to extract the missing user demographics from textual data, such as user posts and personal descriptions.
用户人口统计数据在塑造用户行为方面起着关键作用,因此需要开发更广泛的用户角色,以便能够真实且合理地模拟他们的行为。
然而,由于直接从社交媒体获得的用户信息的可用性有限,因此必须从文本数据(例如用户帖子和个人描述)中提取缺失的用户人口统计数据。
Specifically, we capture user demographic features from textual information using LLM, with a particular emphasis on predicting Age, Gender, and Occupation. By integrating demographic attributes inferred from social network data, we are able to present an enhanced and more authentic representation of users’ actions and interactions.
具体来说,我们使用 LLM从文本信息中捕获用户人口统计特征,特别强调预测 Age、Gender 和 Occupation。
通过整合从社交网络数据中推断出的人口统计属性,我们能够呈现用户行为和互动的增强和更真实的表示。
==研究焦点与数据选取==
3.3 Individual-level Simulation 个人层面的模拟
Utilizing the initialized social network environment, the system commences the simulation at an individual level. Precisely, the user acquires awareness of the information environment, thereby influencing their emotions and attitude. Subsequently, the user is granted the option to forward (repost) observed posts, generate new content, or keep inactive. In essence, we conduct individual simulations encompassing three facets: emotion, attitude, and interaction behavior.
利用初始化的社交网络环境,系统在个人层面开始模拟。
准确地说,用户获得了对信息环境的意识,从而影响了他们的情绪和态度。
随后,用户被授予转发(重新发布)观察到的帖子、生成新内容或保持非活动状态的选项。
从本质上讲,我们进行单独的模拟,包括三个方面:情绪、态度和交互行为。
3.3.1 Emotion Simulation 情绪模拟
In the process of disseminating real-world events, when a user with their own cognition, attitudes, and personality encounters an event, they are often triggered emotionally and express their emotions on social platforms. Emulating user emotions is crucial for social network simulations, as it significantly influences how users convey their intended messages. However, simulating emotions is challenging due to the multitude of factors and complex relationships involved in human emotions. Leveraging the rich knowledge of human behavior inherent in LLMs, we employ LLM to simulate individual emotions.
在传播现实世界事件的过程中,当具有自身认知、态度和性格的用户遇到事件时,他们往往会被情绪触发,并在社交平台上表达自己的情绪。
模拟用户情绪对于社交网络模拟至关重要,因为它会显著影响用户传达预期信息的方式。
然而,由于人类情感涉及多种因素和复杂的关系,模拟情感具有挑战性。
利用 LLMs中固有的丰富的人类行为知识,我们用它来LLM模拟个人情绪。
Specifically, we model the potential emotions of users towards a particular event as three levels: calm, moderate, and intense. Initially, when users are unaware of the event, their default emotion level is set to calm. However, as they become aware of the event, their emotional state begins to evolve. In order to capture this dynamic nature of emotions, we employ a Markov process. This process considers several factors, including the user’s current emotion level, user profiles, user history, and the messages received at the present time step. By integrating these variables, we can predict the user’s emotion level in the subsequent time step.
具体来说,我们将用户对特定事件的潜在情绪建模为三个级别:平静、适度和强烈。
最初,当用户不知道事件时,他们的默认情绪级别将设置为 calm 。
然而,当他们意识到这一事件时,他们的情绪状态开始发生变化。
为了捕捉情绪的这种动态性质,我们采用了马尔可夫过程。[Markov process 是一种随机过程,其特点是未来状态仅依赖于当前状态,而与过去的状态无关。这种性质被称为“无记忆性”或“马尔可夫性”。]
此过程会考虑多个因素,包括用户的当前情绪水平、用户配置文件、用户历史记录以及当前时间步收到的消息。
通过整合这些变量,我们可以预测用户在接下来的时间步中的情绪水平。
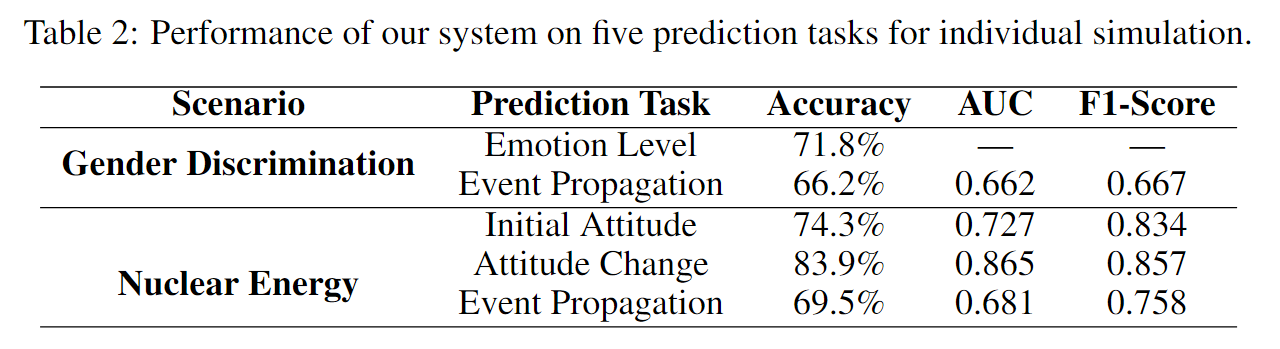
Our emotion simulation approach has yielded promising results at the individual level. As shown in Table 2, using real-world data for evaluation, our method demonstrates good performance in predicting the emotions of the next time step. We achieve an accuracy of 71.8% in this three-classification task, thanks to the excellent modeling and understanding of human emotional expression by large language models.
我们的情绪模拟方法在个人层面上产生了可喜的结果。
如表 2 所示,使用真实世界的数据进行评估,我们的方法在预测下一个时间步的情绪方面表现出良好的性能。在
这个三分类任务中,我们实现了 71.8% 的准确率,这要归功于大型语言模型对人类情感表达的出色建模和理解。
3.3.2 Attitude Simulation 状态模拟
Just as emulating user emotions proves pivotal for social network simulations, simulating user attitudes carries equal weight. The reproduction of attitudes in a virtual social environment is complex yet indispensable. It is the combination of these attitudes that guide users’ actions, opinions, and decisions about different topics. The challenge in this simulation lies in the multifaceted and subjective nature of attitudes, which are influenced by a wide range of internal and external factors, from individual experiences and beliefs to societal influences and perceived norms.
正如模拟用户情绪在社交网络模拟中至关重要一样,模拟用户态度也同样重要。
在虚拟社会环境中,态度的复制是复杂的,但又是必不可少的。
正是这些态度的结合指导了用户对不同主题的行为、意见和决定。
这种模拟的挑战在于态度的多面性和主观性,这些态度受到广泛的内部和外部因素的影响,从个人经验和信仰到社会影响和感知规范。
For our simulation, we assume that users have initial attitudes towards specific issues, which change based on unfolding events. This dynamic adaptation of attitudes is reflective of real-world social interactions, where people modify their views in response to changing circumstances, influential figures, or compelling arguments.
在我们的模拟中,我们假设用户对特定问题有最初的态度,这些问题会根据事件的发展而变化。
这种态度的动态适应反映了现实世界的社会互动,人们会根据不断变化的环境、有影响力的人物或令人信服的论点来改变他们的观点。
In our model, much akin to the emotional state, we track the users’ attitudes on a binary spectrum, which consists only of negative and positive stances towards an event. Our first step is to establish an initial state for the user’s attitude. This is derived from the user profiles and user history, reflecting their predispositions based on past interactions and behaviors. Once the initial state is established, the dynamics of attitude changes are modeled as a Markov process. The subsequent evolution of these attitudes incorporates not only the user’s current attitude but also their profile, history, and the messages received at the current time step. These factors are collectively employed to predict the user’s attitude in the ensuing time step. Both the initial attitude and the assessment of attitude change are determined based on the LLM.
在我们的模型中,与情绪状态非常相似,我们在二元光谱上跟踪用户的态度,该光谱仅包括对事件的消极和积极立场。
我们的第一步是建立用户态度的初始状态。
这是从用户档案和用户历史记录中得出的,反映了他们基于过去的交互和行为的倾向。
一旦建立了初始状态,态度变化的动力学就被建模为马尔可夫过程。
这些态度的后续演变不仅包括用户当前的态度,还包括他们的个人资料、历史和在当前时间步收到的信息。
这些因素共同用于预测用户在接下来的时间步中的态度。
初始态度和态度变化的评估都是根据LLM确定的。
As depicted in Table 2, our methods have demonstrated excellent performance. In the task of predicting initial attitudes, our approach yields an accuracy of 74.3%, an AUC score of 0.727, and an F1-Score of 0.667. In the subsequent task of attitude change prediction, our method performs even better, achieving an impressive accuracy of 83.9%, an AUC score of 0.865, and an F1-Score of 0.857. These results can be largely attributed to the ability of LLMs to profoundly comprehend human behavior and cognition. Such understanding enables a sophisticated interpretation of user-generated content, resulting in a more accurate prediction of users’ attitudes and their evolution over time.
如表 2 所示,我们的方法表现出优异的性能。
在预测初始态度的任务中,我们的方法产生了 74.3% 的准确率、0.727 的 AUC 分数和 0.667 的 F1 分数。
在随后的态度变化预测任务中,我们的方法表现得更好,取得了令人印象深刻的 83.9% 的准确率、0.865 的 AUC 分数和 0.857 的 F1 分数。
这些结果在很大程度上可以归因于深刻理解人类行为和认知的能力LLMs。
这种理解能够对用户生成的内容进行复杂的解释,从而更准确地预测用户的态度及其随时间的变化。
3.3.3 Content-generation Behavior Simulation 内容生成行为模拟
Within the realm of real-world social networks, users shape their content based on their prevailing attitudes and emotions towards distinct events. Emulating this content creation process is an essential, yet complex, aspect of social network simulations. Each piece of generated content acts as a mirror to the user’s internal state and external influences, manifesting their individual perspective on the event at hand. The crux of the challenge is to encapsulate the wide array of expressions and styles that users employ to convey their sentiments, opinions, and reactions.
在现实世界的社交网络领域中,用户根据他们对不同事件的普遍态度和情绪来塑造他们的内容。
模拟此内容创建过程是社交网络模拟的一个重要但复杂的方面。
每个生成的内容都充当用户内部状态和外部影响的镜子,展示了他们对手头事件的个人看法。
挑战的关键是封装用户用来传达他们的情感、意见和反应的各种表达方式和风格。
Leveraging the strengths of LLMs can significantly alleviate this challenge. These models, with their ability to generate text that closely resembles human-like language patterns, facilitate the simulation of user-generated content with high accuracy. By inputting the user’s profile, along with their current attitude or emotional state, these models are capable of generating content that faithfully reproduces what a user might post in response to a particular event.
利用 LLMs 可以显着缓解这一挑战。
这些模型能够生成与类似人类的语言模式非常相似的文本,有助于以高精度模拟用户生成的内容。
通过输入用户的个人资料以及他们当前的态度或情绪状态,这些模型能够生成忠实再现用户为响应特定事件而可能发布的内容的内容。
This approach, informed by the capabilities of large language models, enables us to craft a sophisticated simulation that mirrors the content generation process in real-world social networks. It thereby provides a nuanced understanding of how users’ attitudes and emotions are reflected in their content, offering invaluable insights for the study of social dynamics.
这种方法以大型语言模型的功能为依据,使我们能够制作一个复杂的模拟,以反映真实社交网络中的内容生成过程。因此,它提供了对用户的态度和情绪如何反映在其内容中的细致入微的理解,为研究社会动态提供了宝贵的见解。
As can be seen in Table 2, our methods yield impressive results. In the Gender Discrimination scenario, we achieved a Perplexity score of 19.289 and an average cosine similarity of 0.723 when compared with the actual user-generated text. In the case of the Nuclear Energy scenario, these figures were even more impressive, with a Perplexity score of 16.145 and an average cosine similarity of 0.741.
从表 2 中可以看出,我们的方法产生了令人印象深刻的结果。
在性别歧视场景中,与实际用户生成的文本相比,我们获得了 19.289 的 Perplexity 分数和 0.723 的平均余弦相似度。
在核能情景中,这些数字更加令人印象深刻,困惑度得分为 16.145,平均余弦相似度为 0.741。
These results validate the effectiveness of our approach, where the LLM’s profound comprehension of human cognition and behavior significantly contributes to accurately simulating user-generated content in social network simulations. Thus, our model serves as a powerful tool in understanding and predicting social dynamics in various contexts.
这些结果验证了我们方法的有效性,其中 LLM对人类认知和行为的深刻理解显着有助于在社交网络模拟中准确模拟用户生成的内容。
因此,我们的模型是理解和预测各种情况下的社会动态的有力工具。
3.3.4 Interactive Behavior Simulation 交互式行为模拟
During the simulation, upon receiving a message from one of their followees, the user is faced with a consequential decision: whether to engage in forwarding, posting new content or do nothing.
在模拟过程中,在收到来自他们的一个追随者的消息后,用户面临着一个重要的决定:是参与转发、发布新内容还是什么都不做。
Effectively modeling the decision-making process is important in simulating information propagation.
有效地对决策过程进行建模对于模拟信息传播非常重要。
Through our data-driven approach, we utilize Large Language Models (LLMs) to simulate users’ interaction behavior by capturing the intricate relationship between users and contexts. The input is the information environment that the user senses, and the LLM-empowered agent make the decision by learning from the observed real data.
通过我们的数据驱动方法,我们利用大型语言模型 LLMs 通过捕获用户与上下文之间的复杂关系来模拟用户的交互行为。
输入是用户感知到的信息环境,LLM授权代理通过从观察到的真实数据中学习来做出决策。
Our model has demonstrated commendable efficacy in this regard. In the scenario of Gender Discrimination, our model achieved an Accuracy of 66.2%, AUC of 0.662, and F1-Score of 0.667. Progressing to the Nuclear Energy context, the model’s performance remained robust, with an Accuracy of 69.5%, AUC of 0.681, and F1-Score of 0.758.
我们的模型在这方面显示出值得称道的功效。在性别歧视的情况下,我们的模型实现了 66.2% 的准确率、0.662 的 AUC 和 0.667 的 F1 分数。
进入核能背景,该模型的性能仍然稳健,准确率为 69.5%,AUC 为 0.681,F1 分数为 0.758。
These promising results not only attest to the LLM’s capability in accurately simulating individual user behavior but also pave the way for exploring its potential at a larger scale. This accomplishment forms the basis for the population-level simulation, which we will delve into in the subsequent sections.
这些有希望的结果不仅证明了 LLM准确模拟个人用户行为的能力,也为更大规模地探索其潜力铺平了道路。这一成就构成了种群水平模拟的基础,我们将在后续部分中深入探讨。
3.4 Population-level Simulation 种群水平模拟
In S3, we capture three forms of propagation, including the propagation of information, emotion, and attitude. Here information propagation focuses on the transmission of news that describes events in social environments. Emotion propagation emphasizes the social contagion of people’s feelings toward specific events or topics. Attitude propagation describes that people exchange their attitudes or viewpoints in the social network. Subsequently, we shall expound upon our comprehensive capacity to simulate these three aforementioned forms of propagation.
在 S3 中,我们捕捉了三种形式的传播,包括信息的传播、情感和态度。
在这里,信息传播侧重于描述社会环境中事件的新闻的传输。
情感传播强调人们对特定事件或话题的情感的社会传染。
态度传播描述了人们在社交网络中交换他们的态度或观点。
随后,我们将阐述我们模拟上述三种传播形式的综合能力。
3.4.1 Information Propagatio 信息传播
With the widespread adoption of digital media, the propagation of information experiences a significant acceleration lorenz2023systematic; luding2005information. In the context of a simulation system designed to mimic social networks, one of its paramount functionalities lies in accurately modeling the process of information propagation and delineating crucial phase transitions xie2021detecting; notarmuzi2022universality. For example, Notarmuzi et al. notarmuzi2022universality conducted extensive empirical studies on a large scale, successfully distilling the concepts of universality, criticality, and complexity associated with information propagation in social media. Meanwhile, Xie et al. xie2021detecting expanded upon the widely accepted percolation theory and skillfully captured the intricate phase transitions inherent in the spread of information on social media platforms.
随着数字媒体的广泛采用,信息的传播经历了显着加速。
在旨在模拟社交网络的模拟系统的上下文中,其最重要的功能之一在于准确建模信息传播过程并描绘关键的相变。
例如,Notarmuzi进行了大规模的广泛实证研究,成功地提炼出与社交媒体信息传播相关的普遍性、关键性和复杂性的概念。
与此同时,Xie扩展了被广泛接受的渗流理论,并巧妙地捕捉了社交媒体平台上信息传播中固有的复杂相变。
Diverging from previous studies grounded in physical models, our approach adopts a LLM perspective to capture the dynamics of the information propagation process. In order to ascertain the efficacy of our proposed S3 model, we have selected two typical events: (i) Eight-child Mother Event and (ii) Japan Nuclear Wastewater Release Event. The former event came to public attention in late January 2022, encompassing a range of contentious issues, such as sexual assault and feminism. The latter event entails Japan’s government’s decision to release nuclear wastewater into the ocean, eliciting significant global scrutiny and interest.
与以前基于物理模型的研究不同,我们的方法采用一种LLM视角来捕捉信息传播过程的动态。
为了确定我们提出的 S3 模型的有效性,我们选择了两个典型事件:(i) 八孩母亲事件和 (ii) 日本核废水排放事件。
前者事件于 2022 年 1 月下旬引起公众关注,涉及一系列有争议的问题,例如性侵犯和女权主义。
后一事件导致日本政府决定将核废水排放到海洋中,引起了全球的密切关注和兴趣。
Utilizing our simulator as a foundation, we employ a quantitative approach to evaluate the temporal dissemination of the aforementioned occurrence. This is achieved by calculating the overall number of people who have known the events at each time step (refer to Figure 2(b) and Figure 3(b)). Subsequently, through a comparative analysis with the empirical data (as illustrated in Figure 2(a) and Figure 3(a)), we discern that our simulator exhibits a commendable capacity for accurately forecasting the propagation patterns of both events. In particular, we notice that the rate of rise becomes gradually marginal over time, which can also be captured by our simulator.
利用我们的模拟器作为基础,我们采用定量方法来评估上述事件的时间传播。
这是通过计算每个时间步长知道事件的总数来实现的(参见图 2(b) 和图 3(b))。
随后,通过与经验数据的比较分析(如图 2(a) 和图 3(a) 所示),我们发现我们的模拟器在准确预测这两个事件的传播模式方面表现出值得称道的能力。
特别是,我们注意到上升速率随着时间的推移逐渐变得微不足道,这也可以被我们的模拟器捕获。
3.4.2 Emotion Propagation 情感传播
Another indispensable form of propagation is the transmission of emotion on social media wang2022global; schafer2002spinning. For example, Wang et al. wang2022global adopt the natural language processing techniques (BERT) and perform frequent global measurements of emotion states to gauge the impacts of pandemic and related policies. In S3, we utilize the state-of-the-art LLM to extract emotions from real-world data and simulate the emotional propagation among LLM-based agents.
另一种不可或缺的传播形式,就是在社交媒体上传递情感。
例如,Wang et al. wang2022global 采用自然语言处理技术 (BERT) 并频繁地对情绪状态进行全球测量,以衡量大流行和相关政策的影响。
在 S3 中,我们利用最先进的技术LLM从真实世界的数据中提取情绪,并模拟基于智能体之间的LLM情绪传播。
To examine whether the S3 simulator can also reproduce the emotion propagation process, we further simulate users’ emotions expressed in the Eight-child Mother event. We extract the emotional density from the textual interactions among agents. Comparing our simulation results (Figure 2(d)) and the empirical observations (Figure 2(c)), we find that our model can well capture the dynamic process of emotion propagation. Notably, we observe that there are two emotional peaks in the event. This suggests that if news of the event spreads more slowly across a larger community, a secondary peak in emotional intensity may occur. Based on the initialization obtained from real-world data, our model successfully reproduces these distinct peaks, thereby demonstrating the effectiveness of our proposed S3 system.
为了研究 S3 模拟器是否也能再现情绪传播过程,我们进一步模拟了用户在八孩妈妈事件中表达的情绪。
我们从代理之间的文本交互中提取情感密度。
比较我们的模拟结果(图 2(d))和实证观察(图 2(c)),我们发现我们的模型可以很好地捕捉情绪传播的动态过程。
值得注意的是,我们观察到该事件有两个情绪高峰。
这表明,如果事件的消息在更大的社区中传播得更慢,则可能会出现情绪强度的第二个高峰。
基于从真实世界数据中获得的初始化,我们的模型成功地再现了这些不同的峰,从而证明了我们提出的 S3 系统的有效性。
3.4.3 Attitude Propagation 态度传播
One of today’s most concerning issues is the polarization and confrontation between populations with diverging attitudes toward controversial topics or events. Great efforts have been made to quantify real-world polarization lorenz2023systematic; flamino2023political; hohmann2023quantifying and simulate the polarization process using co-evolution model santos2021link; baumann2020modeling; baumann2021emergence; liu2023emergence. In S3, we use LLM to simulate propagation attitudes and predict polarization patterns in social networks.
当今最令人担忧的问题之一是对有争议的话题或事件持不同态度的人群之间的两极分化和对抗。
已经付出了巨大的努力来量化现实世界的极化并使用协同进化模型 Santos2021 链接模拟极化过程。
在 S3 中,我们用来LLM模拟传播姿态并预测社交网络中的极化模式。
Here we focus on the Japan Nuclear Wastewater Release Event, in which people’s attitudes are polarized toward nuclear energy. As shown in Figure 3, we can observe that with the propagation of related information, positive attitudes toward nuclear energy decline rapidly, exhibiting a salient trough. In our S3 model, though modeling repeated interactions among agents, we reproduce the sudden decrease in positive attitudes and also capture their gradual increase. Overall, these observations suggest that our proposed model can not only simulate attitude propagation but also capture the critical dynamical patterns when situated in real-world scenarios.
在这里,我们关注日本核废水排放事件,其中人们对核能的态度两极分化。
如图 3 所示,我们可以观察到,随着相关信息的传播,人们对核能的积极态度迅速下降,呈现出明显的低谷。
在我们的 S3 模型中,通过对代理之间的重复互动进行建模,我们再现了积极态度的突然下降,并捕捉了它们的逐渐增加。
总的来说,这些观察结果表明,我们提出的模型不仅可以模拟姿态传播,还可以在真实场景中捕获关键的动力学模式。
4 Architecture and Methodology
4架构和方法
4.1 Architecture Design
4.1架构设计
In order to simulate the process of information propagation on the online social network, we have designed a message propagation simulation framework illustrated in Figure 1 and is explained in detail below.
为了模拟在线社交网络上的信息传播过程,我们设计了一个消息传播模拟框架,如图 1 所示,下面将详细解释。
Environment Construction: The construction of the environment involves the formation of a social network on a public platform, comprising users and connections among them. For instance, users have the ability to establish mutual following relationships with their friends, or one-way following relationships with users they find interesting. Hence, the social network can be characterized as a directed graph, where the outdegree and indegree of nodes in the network represent the number of people they follow and the number of followers they possess, respectively. The users within this network can be broadly categorized into three groups: influential users, regular users, and low-impact users. Influential users typically exhibit a significantly larger number of followers compared to the number of people they follow. Moreover, they demonstrate a tendency to share high-quality original information. Regular users, on the other hand, typically maintain a balanced proportion of followers and followings. Additionally, a considerable portion of regular users engage in mutual following relationships, which often reflect their real-life friendships. Conversely, low-impact users exhibit limited followers, infrequent message posting, and typically represent the terminal points of message propagation chains. It is important to note that within this framework, we have excluded the consideration of social bots and zombie users, despite their prevalence on social platforms.
环境建设:环境的建设涉及在公共平台上形成社交网络,包括用户和他们之间的联系。例如,用户能够与他们的朋友建立相互关注的关系,或者与他们感兴趣的用户建立单向关注关系。因此,社交网络可以被描述为有向图,其中网络中节点的出度和入度分别代表他们关注的人数和他们拥有的追随者数量。此网络中的用户大致可分为三组:有影响力的用户、普通用户和低影响用户。与他们关注的人数相比,有影响力的用户通常表现出更多的关注者数量。此外,他们表现出分享高质量原始信息的倾向。另一方面,普通用户通常保持追随者和追随者的平衡比例。此外,相当一部分普通用户参与相互关注的关系,这通常反映了他们现实生活中的友谊。相反,低影响用户表现出关注者有限、消息发布不频繁,并且通常代表消息传播链的终点。需要注意的是,在此框架内,我们排除了对社交机器人和僵尸用户的考虑,尽管它们在社交平台上很普遍。
User Characterization In addition to the social relationships present within the network, each user possesses their own attribute descriptions. Certain attributes are objective and specific, encompassing factors such as gender, occupation, and age. On the other hand, other attributes are more abstract, including their attitudes towards specific events and their prevailing emotional states. The former attributes tend to exhibit minimal fluctuations over short durations, whereas the latter attributes are more dynamic, particularly when users engage in information browsing on social platforms. In such cases, their fundamental attributes, message content, and message sources consistently shape their attitudes, emotions, and other abstract attributes. In light of the aforementioned descriptions, we also introduce a memory pool for each user. Given the abundance of messages from diverse users on online public platforms, a multitude of messages emerge daily. It is important to acknowledge that different messages exert varying influences on distinct users. To address this, we draw inspiration from park2023generative and propose the concept of influence factors. These factors calculate weighted scores based on parameters such as posting time, content relevance, and message importance. By doing so, we ensure that the user’s memory pool retains the most impactful messages, making them highly memorable.
用户特征描述 除了网络中存在的社会关系外,每个用户还拥有自己的属性描述。某些属性是客观和具体的,包括性别、职业和年龄等因素。另一方面,其他属性则更加抽象,包括他们对特定事件的态度和他们普遍的情绪状态。前者属性往往在短时间内表现出最小的波动,而后一个属性则更加动态,尤其是当用户在社交平台上浏览信息时。在这种情况下,它们的基本属性、消息内容和消息源始终塑造着它们的态度、情感和其他抽象属性。 鉴于上述描述,我们还为每个用户引入了一个内存池。鉴于在线公共平台上来自不同用户的大量消息,每天都会出现大量消息。重要的是要承认不同的消息对不同的用户施加不同的影响。为了解决这个问题,我们从 park2023generative 中汲取灵感,并提出了影响因素的概念。这些因素根据发布时间、内容相关性和消息重要性等参数计算加权分数。通过这样做,我们确保用户的内存池保留最具影响力的消息,使它们非常令人难忘。
• Temporal Influence: The recency of messages plays a significant role in human memory, with previous messages gradually fading over time. A time score is ascribed to messages using a prescribed forgetting function.
时间影响:消息的近因在人类记忆中起着重要作用,之前的消息会随着时间的推移逐渐消失。使用规定的遗忘函数将时间分数归因于消息。
• Content Relevance: The relevance of message content is assessed with regard to the user’s individual characteristics. Notably, younger individuals tend to exhibit a greater inclination towards entertainment-related events, whereas middle-aged individuals demonstrate heightened interest in political affairs. To quantify the degree of relevance, a relevance score is obtained by measuring the cosine similarity between a user’s fundamental attributes and the content of the message.
内容相关性:根据用户的个人特征评估消息内容的相关性。值得注意的是,年轻人往往对娱乐相关活动表现出更大的倾向,而中年人则对政治事务表现出浓厚的兴趣。为了量化相关性的程度,通过测量用户的基本属性与消息内容之间的余弦相似性来获得相关性分数。
• Message Authenticity: The authenticity of messages is closely related to their sources. Messages are categorized based on their origins, encompassing messages disseminated by unidirectional followers, messages shared by mutual followers, messages recommended by the platform, and messages previously posted by the user themselves. Distinct scores are assigned to messages based on their respective sources.
消息真实性:消息的真实性与其来源密切相关。消息根据其来源进行分类,包括单向关注者传播的消息、共同关注者分享的消息、平台推荐的消息以及用户自己之前发布的消息。根据消息各自的来源为消息分配不同的分数。
Update and Evolution Mechanism: During a social gathering, various official accounts and individual users contribute posts concerning the event, encompassing news reports and personal viewpoints. Upon encountering these messages, the users who follow them manifest diverse emotional responses. Some users may even formulate their own stances on contentious matters, either in support or opposition, subsequently engaging in online activities such as endorsing, disseminating, and creating original message. In this simulation, we employ large language models to replicate individual users, leveraging their profiles and memory pools as prompts to generate cognitive reactions and behavioral responses. Subsequently, their abstract attributes and memory pools undergo updates. Following the modification of a user’s memory pool, these messages disseminate and exert influence on their followers while they peruse the content. This iterative process persists, emulating the propagation of messages and the evolution of individuals’ cognitive states.
更新和进化机制:在社交聚会期间,各种官方账号和个人用户都会发布有关活动的帖子,包括新闻报道和个人观点。在遇到这些消息时,关注它们的用户会表现出不同的情绪反应。一些用户甚至可能对有争议的事项形成自己的立场,无论是支持还是反对,随后参与在线活动,例如认可、传播和创建原创信息。在这个模拟中,我们采用大型语言模型来复制个人用户,利用他们的个人资料和内存池作为提示来生成认知反应和行为反应。随后,它们的抽象属性和内存池将进行更新。在用户的内存池被修改后,这些消息会在他们的追随者细读内容时传播并施加影响。这个迭代过程持续存在,模拟信息的传播和个人认知状态的演变。
4.2 Initialization 初始化
4.2.1 Social Network Construction 社交网络建设
Within the scope of this study, we propose an initialization approach to construct a network utilizing data acquired from real-world social media sources (refer to Table 1). Strict adherence to privacy regulations and policies is maintained throughout the collection of social media data. Our approach leverages keyword-matching techniques to effectively extract posts relevant to the simulated scenarios. Subsequently, we delve into the identification of the authors and extract them as the foundational nodes of our network. Expanding beyond the individual level, we meticulously gather socially connected users. To establish connections between users, directed edges are established if the corresponding followee exists within the extracted user set. To optimize simulation efficiency, in this work, we focus solely on this sub-graph rather than the entire graph which is too large. During the simulation, the dissemination of messages occurs exclusively between source nodes and their corresponding target nodes.
在本研究的范围内,我们提出了一种初始化方法,利用从真实世界社交媒体来源获得的数据来构建网络(参见表 1)。在整个社交媒体数据收集过程中,我们严格遵守隐私法规和政策。我们的方法利用关键字匹配技术来有效地提取与模拟场景相关的帖子。随后,我们深入研究了作者的身份,并将他们提取为我们网络的基础节点。超越个人层面,我们精心聚集了社交用户。为了在用户之间建立连接,如果提取的用户集中存在相应的关注者,则会建立定向边缘。为了优化仿真效率,在这项工作中,我们只关注这个子图,而不是太大的整个图。在模拟期间,消息的传播仅发生在源节点及其相应的目标节点之间。
4.2.2 User Demographics Prediction 用户人口统计预测
Expanding upon the properties of the node, specifically focusing on user demographic attributes, emerges as a pivotal stride in our endeavor towards a more exhaustive simulation. Through the incorporation of additional information regarding the users into the system, we can delve into and scrutinize their behaviors, interactions, and influence within the network, more effectively. User demographic attributes allow us to capture heterogeneity and diversity in real-world social networks. That is, demographic attributes play a significant role in shaping individual behaviors and preferences, which, in turn, influence the network’s overall attitude dynamics. In our study, we chose gender, age, and occupation as the major demographic attributes. As social media data does not directly offer attributes such as gender, age, and occupation, we rely on prediction techniques to estimate these attributes. Leveraging LLMs provides a robust approach to predicting these demographic attributes. By utilizing LLMs, we can leverage the extensive contextual understanding and knowledge encoded within the models to infer user demographics based on available information, such as personal descriptions and content within posts. The technical details are as follows.
扩展节点的属性,特别是关注用户人口统计属性,是我们努力实现更详尽模拟的关键一步。通过将有关用户的其他信息整合到系统中,我们可以更有效地深入研究和审查他们在网络中的行为、互动和影响。用户人口统计属性使我们能够捕捉现实世界社交网络中的异质性和多样性。也就是说,人口统计属性在塑造个人行为和偏好方面起着重要作用,这反过来又会影响网络的整体态度动态。在我们的研究中,我们选择性别、年龄和职业作为主要的人口统计属性。由于社交媒体数据不直接提供性别、年龄和职业等属性,因此我们依靠预测技术来估计这些属性。利用提供了一种LLMs强大的方法来预测这些人口统计属性。通过利用 LLMs,我们可以利用模型中编码的广泛上下文理解和知识,根据可用信息(例如个人描述和帖子中的内容)推断用户人口统计数据。技术细节如下。
User Demographics Prediction with LLM. In order to predict user gender based on personal descriptions, since the collected data lacks sufficient labels, we use a public dataset released in 10.1145/3219819.3220077; 10.1145/2700398 for assistance. It allows us to extract a vast array of labeled gender and personal description relationships. We filter out data with longer than 10 words in this dataset served as the ground truth to tune the language model. Specifically, we use ChatGLM du-etal-2022-glm as the foundation model and employ the P-Tuning-v2 liu-etal-2022-p methodology. We feed the model with the personal description as a prompt and let the model determine the most probable gender associated with the given description.
用户LLM人口统计预测 . 为了根据个人描述预测用户性别,由于采集到的数据缺乏足够的标签,我们使用了 10.1145/3219819.3220077发布的公共数据集;10.1145/2700398 寻求帮助。它允许我们提取大量标记的性别和个人描述关系。我们在此数据集中过滤掉超过 10 个单词的数据,作为调整语言模型的地面实况。具体来说,我们使用 ChatGLM du-etal-2022-glm 作为基础模型,并采用 P-Tuning-v2 liu-etal-2022-p 方法。我们将个人描述作为提示提供给模型,并让模型确定与给定描述相关的最可能的性别。
To predict age using users’ posts, we use Blog Authorship Corpus Dataset schler2006effects dataset to establish the expression-to-age relationship. This dataset provides us with author-age labels for corresponding textual posts. We randomly select the historical blogs in schler2006effects and add them to the prompt as input; then, the age can be used as the label for prefix tuning. The tuned large language model can be used to predict the age label in our collected social media dataset.
为了使用用户的帖子预测年龄,我们使用 Blog Authorship Corpus Dataset schler2006effects 数据集来建立表达式与年龄的关系。此数据集为我们提供了相应文本帖子的作者年龄标签。我们在 schler2006effects 中随机选择历史博客,并将它们作为输入添加到 Prompt 中;然后,可以将 age 用作前缀优化的标签。调整后的大型语言模型可用于预测我们收集的社交媒体数据集中的年龄标签。
Next, we predict occupations only using pre-trained LLMs. In this scenario, we directly feed users’ posts and personal profile descriptions to the LLM for prediction. By examining the content of these inputs, the model showcased its capacity to comprehend and infer users’ occupations, further enhancing our demographic prediction capabilities.
接下来,我们只使用 pre-trained LLMs来预测职业。在这种情况下,我们直接将用户的帖子和个人个人资料描述提供给 LLM for prediction。通过检查这些输入的内容,该模型展示了其理解和推断用户职业的能力,进一步增强了我们的人口预测能力。
Prediction Result Evaluation
预测结果评估
The outcomes of our age and gender prediction analysis are presented in Table 5. Our gender predictor, which relies on a fine-tuned Large Language Model (LLM), achieves satisfactory results. Despite the absence of explicit gender information in all personal descriptions, the predictor successfully generates valid predictions. Moving on to age, we select English blogs from schler2006effects and ensured similar age distribution across the training and testing process. The results show that the mean squared error (MSE) was 128, while the mean absolute error (MAE) was around 7.53. These values indicate a 21.5% unified percentage error (see Table 5).
我们的年龄和性别预测分析的结果如表 5 所示。我们的性别预测器依赖于微调的大型语言模型 (),LLM取得了令人满意的结果。尽管所有个人描述中都没有明确的性别信息,但预测变量还是成功地生成了有效的预测。继续讨论年龄,我们从 schler2006effects 中选择英文博客,并确保在整个训练和测试过程中具有相似的年龄分布。结果表明,均方误差 (MSE) 为 128,而平均绝对误差 (MAE) 约为 7.53。这些值表示 21.5% 的统一百分比误差(见表 5)。
As for the occupations, we initially include the posts and personal descriptions of the combined user dataset in the prompt. We then feed the prompt to pre-trained ChatGLM to obtain the occupation of each user. We leave the supervised fine-tuning for occupation prediction as future work. It results in a total of 1,016 different occupations being identified from all users. However, utilizing all occupations is not essential since some occupations are very close. Thus, we group all occupations into 10 distinct occupation categories using the LLM, of which the categories can be found in Table 5. By condensing the number of occupations into a smaller set, we are able to simplify the simulation.
至于职业,我们最初在提示中包含组合用户数据集的帖子和个人描述。然后,我们将提示提供给预先训练的 ChatGLM,以获取每个用户的职业。我们将职业预测的监督微调留作未来的工作。它导致从所有用户中总共识别出 1,016 种不同的职业。但是,利用所有职业并不是必需的,因为有些职业非常接近。因此,我们使用 将所有职业分为 10 个不同的职业类别LLM,其中这些类别可以在表 5 中找到。通过将职业数量压缩成一个更小的集合,我们能够简化模拟。
Table 4:Prediction performance of gender and age.
Demographic Performance
Gender Acc F1 AUC
0.710 0.667 0.708
Age MSE MAE Avg % Error
128.0 7.53 21.50
Table 5:Ten occupations.
1 Education Practitioner
2 Administrative Manager / Officer
3 Unemployed / Student
4 Engineer
5 Labor Technician / Worker
6 Logistics Practitioner
7 Medical Personnel
8 Financial Practitioner
9 Media Personnel
10 Entertainment and Arts Practitioner
4.3 Emotion and Attitude Simulation 情绪和态度模拟
In our emotion simulation model, we adopt a Markov chain approach to capture the dynamic process of emotional changes triggered by a user receiving a message. The simulation involves four essential inputs: user demographics, current emotion, the received post. Emotions are classified into three distinct stages: calm, moderate, and intense. User demographics serve as supplementary information LLMs, providing a reference point to contextualize emotional responses. The current emotion represents the user’s emotional status before receiving the post, while the received post acts as the actuator for prompting the LLM to determine a new emotional status.
在我们的情绪模拟模型中,我们采用马尔可夫链方法来捕捉用户收到消息所触发的情绪变化的动态过程。模拟涉及四个基本输入:用户人口统计、当前情绪、收到的帖子。情绪分为三个不同的阶段:平静、适度和强烈。用户人口统计数据作为补充信息LLMs,为将情绪反应置于上下文中提供了一个参考点。当前情绪代表了用户在收到帖子之前的情绪状态,而收到的帖子则充当了提示用户LLM确定新的情绪状态的执行器。
To regulate the decrease of emotional states over time, we introduce the decaying coefficient, a hyper-parameter that controls the decay rate of emotions. Our hypothesis assumes that emotions tend to diminish gradually as time passes, influencing the emotion simulation process. Throughout this intricate mechanism, we impart these details by prompt to the LLMs, which are responsible for deciding whether the emotional state should change in response to the received post. We are trying to reduce as much manual intervention as possible, to highlight the capability of LLMs in simulating emotional changes by posts. The attitude simulation is similar to the emotion simulation.
为了调节情绪状态随时间的下降,我们引入了衰减系数,这是一个控制情绪衰减率的超参数。我们的假设假设情绪往往会随着时间的推移逐渐减少,从而影响情绪模拟过程。在这个错综复杂的机制中,我们通过提示将这些细节传递给 LLMs,它们负责决定情绪状态是否应该根据收到的帖子而改变。我们正在努力减少尽可能多的人工干预,以突出通过帖子模拟情绪变化的能力LLMs。姿态模拟类似于情绪模拟。
4.4 Behavior Simulation 行为模拟
4.4.1 Content-generation Behavior 内容生成行为
In our social network simulation model, we incorporate an advanced approach utilizing Large Language Models (LLMs) to reproduce the dynamic process of content creation, shaped by users’ emotions and attitudes towards specific events. The simulation hinges on two vital inputs: user profile information, and their current emotional or attitudinal state towards the event. Each piece of generated content is an embodiment of a user’s internal state and external influences, reflecting their unique perspective.
在我们的社交网络模拟模型中,我们采用了一种先进的方法,利用大型语言模型 ()LLMs 来重现内容创建的动态过程,该过程由用户对特定事件的情绪和态度塑造。模拟取决于两个重要输入:用户个人资料信息,以及他们当前对事件的情绪或态度状态。每条生成的内容都是用户内部状态和外部影响的体现,反映了他们独特的视角。
User profile information serves as a reference point for the LLMs, furnishing essential context to shape content responses. The current emotional or attitudinal state symbolizes the user’s mindset when reacting to the event, thereby playing a vital role in the LLM’s generation of potential responses.
用户配置文件信息用作 LLMs的参考点,提供必要的上下文来塑造内容响应。当前的情绪或态度状态象征着用户对事件做出反应时的心态,因此在潜在反应的产生中LLM起着至关重要的作用。
Underpinning this sophisticated mechanism is the profound cognitive and behavioral comprehension of LLMs. The LLM is prompted with these details and is then responsible for deciding how the content should be shaped in response to the event. Our aim is to minimize manual intervention as much as possible, to highlight the capability of LLMs in simulating authentic user-generated content.
支撑这种复杂机制的是 的LLMs深刻认知和行为理解。系统会提示 这些LLM详细信息,然后负责决定应如何塑造内容以响应事件。我们的目标是尽可能减少人工干预,以突出模拟真实用户生成内容的能力LLMs。
The approach mirrors the way real-world users form their posts in response to distinct events, aligning the text generation process with the emotional or attitudinal dynamics of users. In this manner, we have been successful in utilizing LLMs to emulate the content creation process on social networks with high fidelity.
该方法反映了真实世界用户根据不同事件形成帖子的方式,使文本生成过程与用户的情绪或态度动态保持一致。通过这种方式,我们已经成功地利用LLMs高保真度模拟社交网络上的内容创建过程。
4.4.2 Interaction Behavior 交互行为
During the simulation, when a user receives a message from one of their followees, a critical decision needs to be made—whether to repost/post or not. That is to say, the interaction behavior includes reposting (forwarding) the original content and posting new content about the same social event. The user’s interaction behavior plays a pivotal role in propagating messages to the user’s followers, facilitating the spread of information within the social network. However, modeling the complex mechanisms governing a user’s interaction behavior poses significant challenges. To address it, we employ large language models to capture the intricate relationship between the user, post features, and interaction behavior.
在模拟过程中,当用户收到来自其关注者的消息时,需要做出关键决策 - 是否转发/发布。也就是说,交互行为包括转发(转发)原始内容和发布有关同一社交事件的新内容。用户的交互行为在将消息传播给用户的关注者方面起着关键作用,促进了信息在社交网络中的传播。然而,对控制用户交互行为的复杂机制进行建模带来了重大挑战。为了解决这个问题,我们采用大型语言模型来捕获用户、帖子特征和交互行为之间的复杂关系。
Specifically, to leverage the ability of LLMs to simulate a real user’s interaction behavior, we prompt the model with information regarding the user’s demographic properties, i.e. gender, age, and occupation, in addition to the specific posts received, letting the LLM think like the user and make its decision. By such means, we enable LLM to make predictions regarding the user’s inclination to repost the message or post new content.
具体来说,为了利用模拟真实用户交互行为的能力LLMs,除了收到的具体帖子外,我们还向模型提示有关用户人口统计属性的信息,即性别、年龄和职业,让用户像用户一样LLM思考并做出决定。通过这种方式,我们可以LLM预测用户转发消息或发布新内容的倾向。
To summarize, by employing the above approach, we can effectively harness the power of LLMs to predict users’ interaction behavior, taking into account various user and post features.
总而言之,通过采用上述方法,我们可以有效地利用预测用户交互行为的能力LLMs,同时考虑到各种用户和帖子特征。
4.5 Other Implementation Details
4,5其他实现细节
The system employs various techniques for utilizing or adapting large language models to the agent-based simulation. For prompting-driven methods, we use either GPT-3.5 API provided by OpenAI1 or a ChatGLM-6B model du-etal-2022-glm. For fine-tuning methods, we conduct the tuning based on the open-source ChatGLM model.
该系统采用各种技术来利用或调整大型语言模型以适应基于代理的模拟。对于提示驱动的方法,我们使用 OpenAI1 提供的 GPT-3.5 API 或 ChatGLM-6B 模型 du-etal-2022-glm。对于微调方法,我们基于开源的 ChatGLM 模型进行微调。
5 Discussions and Open Problems
5讨论和未解决的问题
The S3 system, which has been developed, represents an initial endeavor aimed at harnessing the capabilities of large language models. This is to facilitate simulation within the domain of social science.
已经开发的 S3 系统代表了旨在利用大型语言模型功能的初步努力。这是为了促进社会科学领域的模拟。
In light of this, our analysis delves further into its application and limitations, along with promising future improvements.
有鉴于此,我们的分析进一步深入研究了它的应用和局限性,以及有希望的未来改进。
5.1 Application of S3 System 系统的应用
Leveraging the powerful capabilities of large language models, this system excels in agent-based simulation. The system has the following applications in the field of social science.
利用大型语言模型的强大功能,该系统在基于代理的模拟方面表现出色。该系统在社会科学领域有以下应用。
• Prediction. Prediction is the most fundamental ability of agent-based simulation. Large language model-based simulation can be utilized to predict social phenomena, trends, and individual behaviors with historically collected data. For example, in economics, language models can help forecast market trends, predict consumer behavior, or estimate the impact of policy changes. In sociology, these models can aid in predicting social movements, public opinion shifts, or the adoption of new cultural practices.
预测。预测是基于智能体的模拟的最基本能力。基于大型语言模型的模拟可用于预测社会现象、趋势和个人行为,并利用历史收集的数据。例如,在经济学中,语言模型可以帮助预测市场趋势、预测消费者行为或估计政策变化的影响。在社会学中,这些模型可以帮助预测社会运动、公众舆论转变或新文化实践的采用。
• Reasoning and explanation. During the simulation, each agent can be easily configured, and thus the system can facilitate reasoning and explanation in social science by generating phenomena with different configurations. Comparing the simulation results can provide explain the cause of the specific phenomena. Furthermore, the agent can be observed by prompts which can reflect how a human takes actions in the social environment.
推理和解释。在模拟过程中,每个代理都可以轻松配置,因此系统可以通过生成具有不同配置的现象来促进社会科学中的推理和解释。比较仿真结果可以解释特定现象的原因。此外,可以通过提示来观察代理,这可以反映人类在社会环境中的行为方式。
• Pattern discovery and theory construction. With repeated simulation during the extremely less cost compared with real data collection, the simulation process can reveal some patterns of the social network. By uncovering patterns, these models can contribute to the development of new theories and insights. Furthermore, researchers can configure all the agents and the social network environment, based on an assumption or theory, and observe the simulation results. Testing the simulation results can help validate whether the proposed assumption or theory is correct or not.
模式发现和理论构建。与实际数据收集相比,在成本极低的情况下进行重复模拟,模拟过程可以揭示社交网络的一些模式。通过揭示模式,这些模型有助于开发新的理论和见解。此外,研究人员可以根据假设或理论配置所有代理和社交网络环境,并观察模拟结果。测试仿真结果有助于验证提出的假设或理论是否正确。
• Policy making. The simulation can inform evidence-based policy-making by simulating and evaluating the potential outcomes of different policy interventions. It can assess the impact of policy changes on various social factors, including individual agents and the social environment. For example, in public health, it can simulate the spread of infectious diseases to evaluate the effectiveness of different intervention strategies. In urban planning, it can simulate the impact of transportation policies on traffic congestion or air pollution, by affecting how the users select public transportation. By generating simulations, these models can aid policymakers in making informed decisions.
政策制定。该模拟可以通过模拟和评估不同政策干预措施的潜在结果来为循证决策提供信息。它可以评估政策变化对各种社会因素的影响,包括个体代理和社会环境。例如,在公共卫生方面,它可以模拟传染病的传播,以评估不同干预策略的有效性。在城市规划中,它可以通过影响用户选择公共交通的方式来模拟交通政策对交通拥堵或空气污染的影响。通过生成模拟,这些模型可以帮助政策制定者做出明智的决策。
5.2 Improvement on Individual-level Simulation 个人层面模拟的改进
The current design of individual simulation still has several limitations requiring further improvement. First, the agent requires more prior knowledge of user behavior, including how real humankind senses the social environment and makes decisions. In other words, the simulation should encompass an understanding and integration of intricate contextual elements that exert influence on human behavior. Second, while prior knowledge of user behavior is essential, simulations also need to consider the broader context in which decisions are made. This includes factors such as historical events, social conditions, and personal experiences. By enhancing the agent’s capacity to perceive and interpret contextual cues, more precise simulations can be achieved.
当前单个仿真的设计仍然存在一些需要进一步改进的限制。首先,代理需要更多关于用户行为的先验知识,包括真实的人类如何感知社会环境并做出决策。换句话说,模拟应该包括对影响人类行为的复杂上下文元素的理解和整合。其次,虽然对用户行为的先验知识是必不可少的,但模拟还需要考虑做出决策的更广泛背景。这包括历史事件、社会状况和个人经历等因素。通过增强代理感知和解释上下文线索的能力,可以实现更精确的模拟。
5.3 Improvement on Population-level Simulation 对种群水平模拟的改进
First, it is better to combine agent-based simulation with system dynamics-based methods.
首先,最好将基于智能体的仿真与基于系统动力学的方法相结合。
Agent-based simulation focuses on modeling individual entities and their interactions, while system dynamics focuses on modeling the behavior of the social complex system as a whole. Through the fusion of these two methodologies, we can develop simulations of heightened comprehensiveness, encompassing both micro-level interactions and macro-level systemic behavior. This integration can provide a more accurate representation of population dynamics, including the impact of individual decisions on the overall system.
基于智能体的模拟侧重于对单个实体及其交互进行建模,而系统动力学侧重于对整个社会复杂系统的行为进行建模。通过这两种方法的融合,我们可以开发具有高度综合性的模拟,包括微观层面的互动和宏观层面的系统行为。这种集成可以更准确地表示人口动态,包括个人决策对整个系统的影响。
Second, we can consider a broader range of social phenomena. This involves modeling various societal, economic, and cultural factors that influence human behavior and interactions. Examples of social phenomena to consider include social networks, opinion dynamics, cultural diffusion, income inequality, and infectious disease spread. By incorporating these phenomena into the simulation, we can better validate the system’s effectiveness and also gain more insights into social simulation.
其次,我们可以考虑更广泛的社会现象。这涉及对影响人类行为和互动的各种社会、经济和文化因素进行建模。需要考虑的社会现象示例包括社交网络、意见动态、文化传播、收入不平等和传染病传播。通过将这些现象纳入模拟中,我们可以更好地验证系统的有效性,并更深入地了解社交模拟。
5.4 Improvement on System Architecture Design 系统架构设计的改进
First, we can consider incorporating other channels for social event information. It is essential to acknowledge that social-connected users are not the sole providers of information for individuals within social networks. Consequently, the integration of supplementary data sources has the potential to enrich the individual simulation. For instance, recommender systems can be integrated to gather diverse information about social events. This integration can help capture a wider range of perspectives and increase the realism of the simulation.
首先,我们可以考虑整合其他社交事件信息渠道。必须承认,社交用户并不是社交网络中个人信息的唯一提供者。因此,补充数据源的集成有可能丰富单个模拟。例如,可以集成推荐系统以收集有关社交事件的各种信息。这种集成有助于捕捉更广泛的视角并提高模拟的真实感。
Second, the system architecture should consider improving efficiency, which is essential for running large-scale simulations effectively. Optimizing the system architecture and computational processes can significantly enhance the performance and speed of simulations. To this end, techniques such as parallel computing, distributed computing, and algorithmic optimizations can be employed to reduce computational complexity and advance the efficiency of simulation runs. This allows for faster and more extensive exploration of scenarios, thereby enabling researchers to gain insights faster.
其次,系统架构应考虑提高效率,这对于有效运行大规模仿真至关重要。优化系统架构和计算过程可以显著提高仿真的性能和速度。为此,可以采用并行计算、分布式计算和算法优化等技术来降低计算复杂性并提高仿真运行的效率。这允许更快、更广泛地探索场景,从而使研究人员能够更快地获得见解。
Third, it is essential to add an interface for policy intervention. Including an interface that allows policymakers to interact with the simulation can be beneficial. This interface would enable policymakers to input and test various interventions and policies in a controlled environment. By simulating the potential outcomes of different policy decisions, policymakers can make more informed choices. They can also evaluate the potential impact of their interventions on the simulated population. This feature can facilitate evidence-based decision-making and identify effective strategies.
第三,必须增加一个用于政策干预的界面。包括一个允许政策制定者与模拟交互的界面可能是有益的。该界面将使政策制定者能够在受控环境中输入和测试各种干预措施和政策。通过模拟不同政策决策的潜在结果,政策制定者可以做出更明智的选择。他们还可以评估他们的干预措施对模拟人群的潜在影响。此功能可以促进基于证据的决策并确定有效的策略。
6 Conclusion 结论
In this paper, we present the S3 system (Social Network Simulation System) as a novel approach aimed at tackling the complexities of social network simulation. By harnessing the advanced capabilities of large language models (LLMs) in the realms of perception, cognition, and behavior, we have established a framework for social network emulation. Our simulations concentrate on three pivotal facets: emotion, attitude, and interactive behaviors. This research marks a significant stride forward in social network simulation, pioneering the integration of LLM-empowered agents. Beyond social science, our work possesses the potential to stimulate the development of simulation systems across diverse domains. Employing this methodology enables researchers and policymakers to attain profound insights into intricate social dynamics, thereby facilitating informed decision-making and effectively addressing various societal challenges.
在本文中,我们提出了 S3 系统(社交网络模拟系统)作为一种旨在解决社交网络模拟复杂性的新方法。通过利用大型语言模型 ()LLMs 在感知、认知和行为领域的高级功能,我们建立了社交网络仿真框架。我们的模拟集中在三个关键方面:情感、态度和交互行为。这项研究标志着社交网络模拟向前迈出了重大一步,开创了 LLM-empowered 代理的集成。除了社会科学之外,我们的工作还具有刺激跨不同领域仿真系统发展的潜力。采用这种方法使研究人员和政策制定者能够深入了解错综复杂的社会动态,从而促进明智的决策并有效应对各种社会挑战。
References
[1]Gati V Aher, Rosa I Arriaga, and Adam Tauman Kalai.Using large language models to simulate multiple humans and replicate human subject studies.In International Conference on Machine Learning, pages 337–371. PMLR, 2023.
[2]Robert Axelrod.Advancing the art of simulation in the social sciences.In Simulating social phenomena, pages 21–40. Springer, 1997.
[3]Fabian Baumann, Philipp Lorenz-Spreen, Igor M Sokolov, and Michele Starnini.Modeling echo chambers and polarization dynamics in social networks.Physical Review Letters, 124(4):048301, 2020.
[4]Fabian Baumann, Philipp Lorenz-Spreen, Igor M Sokolov, and Michele Starnini.Emergence of polarized ideological opinions in multidimensional topic spaces.Physical Review X, 11(1):011012, 2021.
[5]Paul Bratley, Bennett L Fox, and Linus E Schrage.A guide to simulation, 1987.
[6]Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al.Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020.
[7]Gary Charness and Matthew Rabin.Understanding social preferences with simple tests.The quarterly journal of economics, 117(3):817–869, 2002.
[8]Bastien Chopard and Michel Droz.Cellular automata.Modelling of Physical, pages 6–13, 1998.
[9]Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al.Palm: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311, 2022.
[10]Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang.GLM: General language model pretraining with autoregressive blank infilling.In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335, Dublin, Ireland, May 2022. Association for Computational Linguistics.
[11]Rohan Anil et al.Palm 2 technical report, 2023.
[12]James Flamino, Alessandro Galeazzi, Stuart Feldman, Michael W Macy, Brendan Cross, Zhenkun Zhou, Matteo Serafino, Alexandre Bovet, Hernán A Makse, and Boleslaw K Szymanski.Political polarization of news media and influencers on twitter in the 2016 and 2020 us presidential elections.Nature Human Behaviour, pages 1–13, 2023.
[13]Jay W Forrester.System dynamics and the lessons of 35 years.In A systems-based approach to policymaking, pages 199–240. Springer, 1993.
[14]Nigel Gilbert and Klaus Troitzsch.Simulation for the social scientist.McGraw-Hill Education (UK), 2005.
[15]Perttu Hämäläinen, Mikke Tavast, and Anton Kunnari.Evaluating large language models in generating synthetic hci research data: a case study.In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–19, 2023.
[16]Marilena Hohmann, Karel Devriendt, and Michele Coscia.Quantifying ideological polarization on a network using generalized euclidean distance.Science Advances, 9(9):eabq2044, 2023.
[17]John J Horton.Large language models as simulated economic agents: What can we learn from homo silicus?Technical report, National Bureau of Economic Research, 2023.
[18]Peter Kolesar and Warren E Walker.A simulation model of police patrol operations: program description.1975.
[19]Lik-Hang Lee, Tristan Braud, Pengyuan Zhou, Lin Wang, Dianlei Xu, Zijun Lin, Abhishek Kumar, Carlos Bermejo, and Pan Hui.All one needs to know about metaverse: A complete survey on technological singularity, virtual ecosystem, and research agenda.arXiv preprint arXiv:2110.05352, 2021.
[20]Jiazhen Liu, Shengda Huang, Nathaniel M Aden, Neil F Johnson, and Chaoming Song.Emergence of polarization in coevolving networks.Physical Review Letters, 130(3):037401, 2023.
[21]Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang.P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks.In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68, Dublin, Ireland, May 2022. Association for Computational Linguistics.
[22]Philipp Lorenz-Spreen, Lisa Oswald, Stephan Lewandowsky, and Ralph Hertwig.A systematic review of worldwide causal and correlational evidence on digital media and democracy.Nature human behaviour, 7(1):74–101, 2023.
[23]Stefan Luding.Information propagation.Nature, 435(7039):159–160, 2005.
[24]Lawrence C Marsh and Meredith Scovill.Using system dynamics to model the social security system.In NBER Workshop on Policy Analysis with Social Security Research Files, pages 15–17, 1978.
[25]Dennis L Meadows, William W Behrens, Donella H Meadows, Roger F Naill, Jørgen Randers, and Erich Zahn.Dynamics of growth in a finite world.Wright-Allen Press Cambridge, MA, 1974.
[26]Daniele Notarmuzi, Claudio Castellano, Alessandro Flammini, Dario Mazzilli, and Filippo Radicchi.Universality, criticality and complexity of information propagation in social media.Nature communications, 13(1):1308, 2022.
[27]OpenAI.Gpt-4 technical report, 2023.
[28]Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein.Generative agents: Interactive simulacra of human behavior.arXiv preprint arXiv:2304.03442, 2023.
[29]Jiezhong Qiu, Jian Tang, Hao Ma, Yuxiao Dong, Kuansan Wang, and Jie Tang.Deepinf: Social influence prediction with deep learning.In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’18, page 2110–2119, New York, NY, USA, 2018. Association for Computing Machinery.
[30]William Samuelson and Richard Zeckhauser.Status quo bias in decision making.Journal of risk and uncertainty, 1:7–59, 1988.
[31]Fernando P Santos, Yphtach Lelkes, and Simon A Levin.Link recommendation algorithms and dynamics of polarization in online social networks.Proceedings of the National Academy of Sciences, 118(50):e2102141118, 2021.
[32]Joseph A Schafer.Spinning the web of hate: Web-based hate propagation by extremist organizations.Journal of Criminal Justice and Popular Culture, 2002.
[33]Jonathan Schler, Moshe Koppel, Shlomo Argamon, and James W Pennebaker.Effects of age and gender on blogging.In AAAI spring symposium: Computational approaches to analyzing weblogs, volume 6, pages 199–205, 2006.
[34]Peter D Spencer.The effect of oil discoveries on the british economy—theoretical ambiguities and the consistent expectations simulation approach.The Economic Journal, 94(375):633–644, 1984.
[35]Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al.Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023.
[36]Klaus G Troitzsch.Social science microsimulation.Springer Science & Business Media, 1996.
[37]Jianghao Wang, Yichun Fan, Juan Palacios, Yuchen Chai, Nicolas Guetta-Jeanrenaud, Nick Obradovich, Chenghu Zhou, and Siqi Zheng.Global evidence of expressed sentiment alterations during the covid-19 pandemic.Nature Human Behaviour, 6(3):349–358, 2022.
[38]Jiarong Xie, Fanhui Meng, Jiachen Sun, Xiao Ma, Gang Yan, and Yanqing Hu.Detecting and modelling real percolation and phase transitions of information on social media.Nature Human Behaviour, 5(9):1161–1168, 2021.
[39]Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al.Glm-130b: An open bilingual pre-trained model.arXiv preprint arXiv:2210.02414, 2022.
[40]Jing Zhang, Jie Tang, Juanzi Li, Yang Liu, and Chunxiao Xing.Who influenced you? predicting retweet via social influence locality.ACM Trans. Knowl. Discov. Data, 9(3), apr 2015.